Beyond Retrieval: Embracing Compressive Memory in Real-World Long-Term Conversations
Brief takeaways
传统的基于检索的方法在 记忆数据管理 和 精确检索 这两个问题上面临挑战。
-
本文提出的 COMEDY 框架避开了检索过程,而是用一个语言模型对记忆进行生成、压缩和基于记忆的内容生成。
-
本文还构建了 Dolphin 数据集,来自于真实人机长对话的中文数据集。
-
验证了COMEDY框架的表现,提升了结果一致性、可预测性,减少了不必要计算和跨模型数据传输。
1. 介绍和贡献
长期对话(long-term conversation)需要对当前对话上下文的精确、深入理解,而且还需要保留、整合过往交互的关键信息。
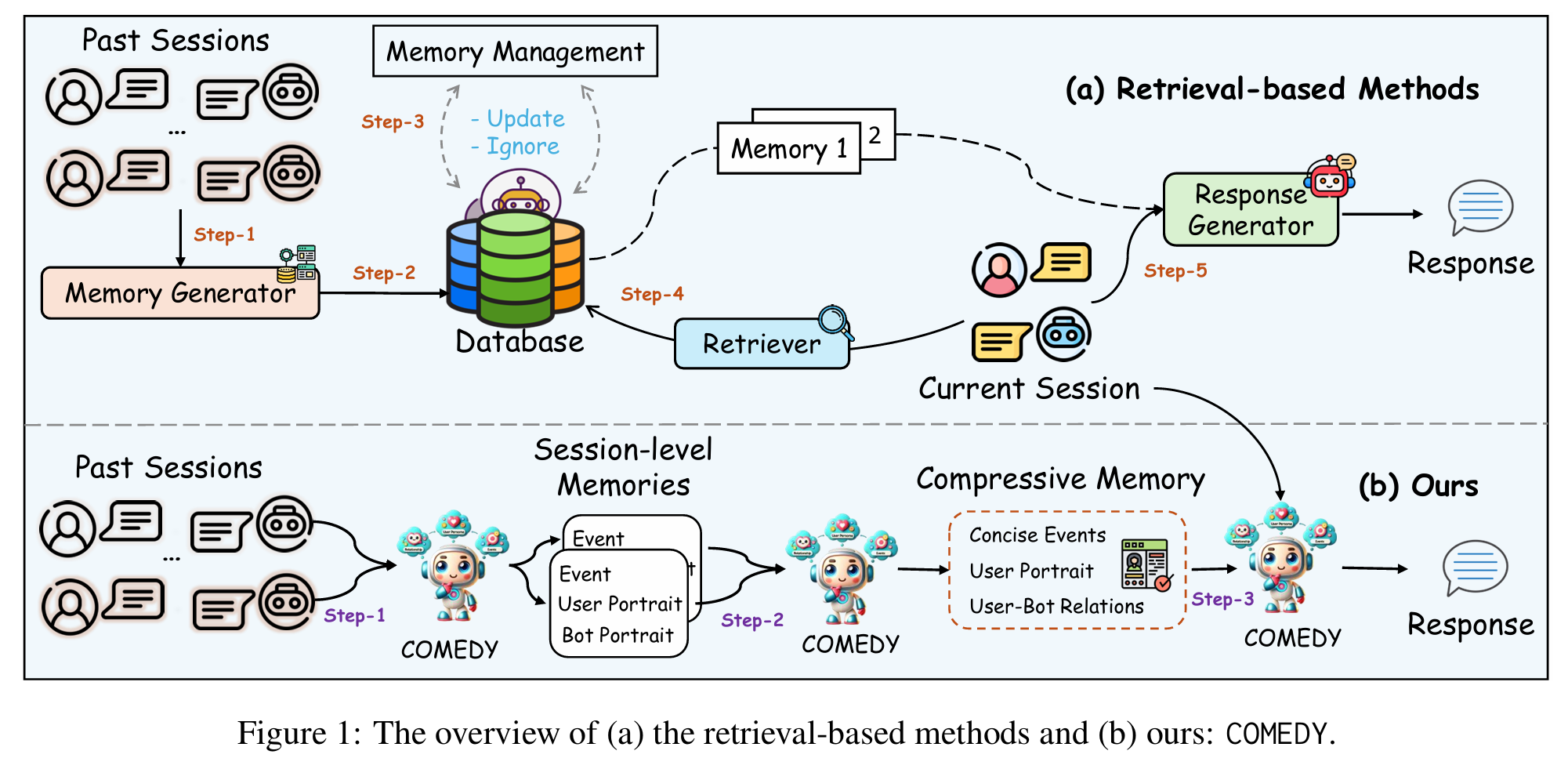
主流方法都是retrieval-based,通常的pipeline是 (1) 从过去对话中总结、生成相关记忆 (2) 用数据库进行记忆存储(及更新) (3) 通过句嵌入模型在数据库中检索相关记忆。 (4) 把检索到的记忆和当前对话喂给模型生成结果。
问题在于:1. 这套系统要求几个模块的良好协作 但就sentence-embedding model就有时不能精确捕捉一些细节和语境。 2. 对于记忆的数据库管理面临着 大小、复杂度的增加 和 对记忆的维护(比如去除过时内容)等挑战。 同时,训练用的语料库很多都是生成数据或众包来的,比较有预测性,真实的对话可能突然转移话题、掺杂口语和一些细微表达,在这种情况下很难保证retrieve model的鲁棒性。
于是提出COMEDY框架,不使用基于检索的方法,而是用一个语言模型对记忆的进行处理。主要有三个任务:
- 对每个Session进行总结提炼
- 对所有Session的summary进行压缩,形成一个 压缩记忆, 包含:用户描述、用户与Bot关系描述、事件描述。
- 根据压缩记忆和当前上下文,生成回答。
同时,构建了中文长上下文数据集Dolphin,来源于X EVA平台中用户和用户自定义bot的真实对话数据。
2. Methodology
(1) Dolphin数据集标注
原始数据来源:X EVA平台的真实对话数据,每组用户-AI对话至少包含15个session,经过筛选清理。
生成初步摘要:利用GPT4-Turbo自动生成每个会话的摘要,提炼出关键信息(如用户情绪、重要事件、用户与Bot的交互亮点等)。
人工标注校正:结合自动生成结果,由专业标注人员对摘要进行核对、修改和补充,确保生成的摘要准确反映会话内容。
为三个任务(会话摘要生成、记忆压缩和基于记忆的回复生成)提供高质量的训练样本。
(2) 多任务训练与端到端对齐
COMEDY模型采用端到端的多任务联合训练策略,同时对三个任务进行微调:
- Task1 - 会话级记忆摘要生成:输入为单个会话的完整对话内容,目标输出为该会话的摘要。
- Task2 - 记忆压缩:将多个会话摘要作为输入,目标输出是一个浓缩、概括性更高的压缩记忆,涵盖用户画像、关键事件和互动动态。
- Task3 - 基于记忆的回复生成:输入包括当前对话上下文和Task 2生成的压缩记忆,目标输出为符合当前语境且体现历史信息的回复。
这三个任务在训练时使用统一的模型,进行端到端微调。
(3) DPO 对齐
在SFT阶段训练后,模型虽能处理三个任务,但在实际生成过程中可能出现回复与压缩记忆不完全一致或幻觉现象。为此,引入了直接偏好优化(DPO)策略,构造正负样本的方法也是通过LLM生成:
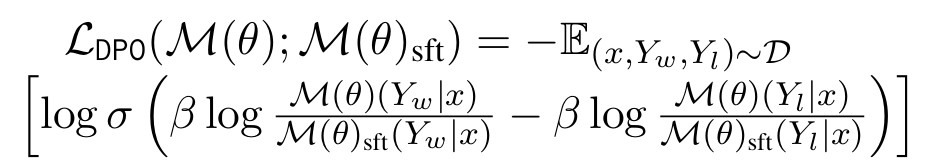
- 构造正负对比样本:
- 正样本:生成的回复与压缩记忆高度一致。
- 负样本:生成的回复与记忆信息不一致。
- 通过极化正负样本的偏好,使模型在优化过程中倾向于选择与记忆一致的回复,从而更好地对齐参考SFT策略。
3. 实验
在LLaMA 2 的 7B、13B的基础上做微调。
baseline
有三类:retrieval-based, context-only approaches 和 other memory-related baselines
基于检索的方法、只直接拼接上下文的方法和其他基于记忆的方法(动态更新记忆库的方法,如MemoryBanks)
- Retrieval-based: 用COMEDY-13B生成记忆(控制变量)+Text2Vec + FAISS
- Context-only: LLaMA (2k context) 、 ChatGPT(8k context)
- Others: MemoryBank-ChatGPT、 Resum-Chatgpt
COMEDY方法
基于LLaMA 2的模型,先做三个任务SFT,再做DPO。
评估
(1) 数据
还是使用X EVA上的数据,选择了 用户与AI bot一周内超过16个session的数据;前15个生成压缩记忆,后1-5个会话作为测试。
(2)指标
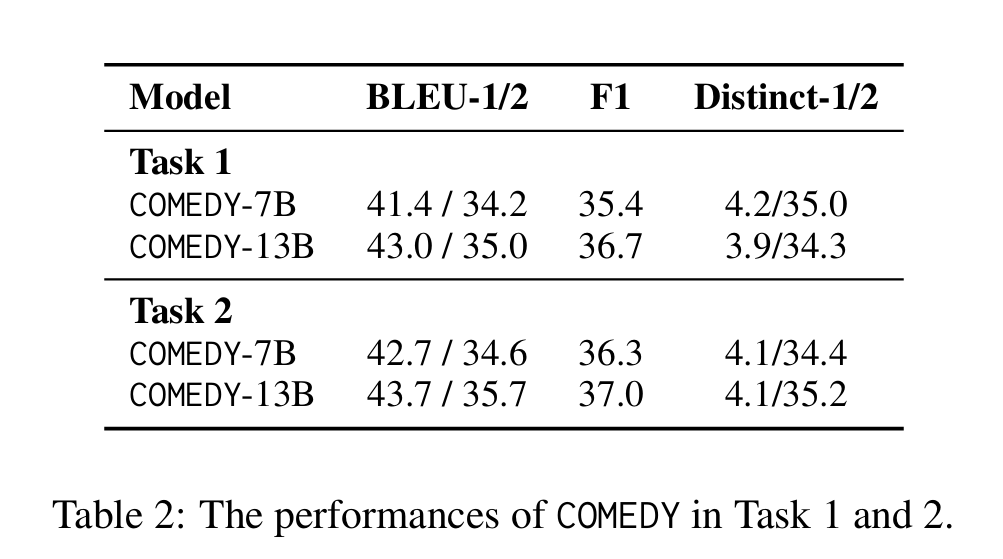
task1 和 task2采取自动指标(BLEU、F1、Distinct)
task3(根据压缩记忆生成)使用人类打分(范围0~3分),包含 评分 和 排序 两组。指标包含:
-
连贯性(Coherence)
-
一致性(Consistency)
-
记忆性(Memorability)
-
吸引力(Engagingness)
-
人性化(Humanness)
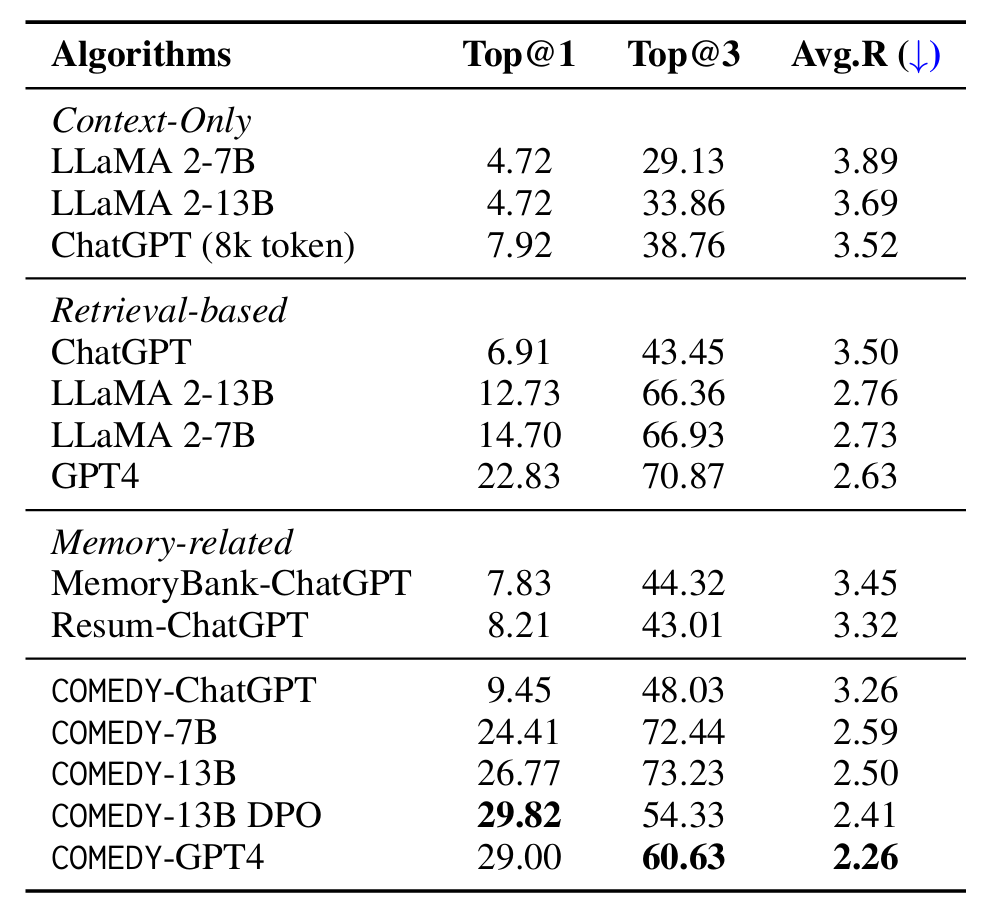
(3)结果
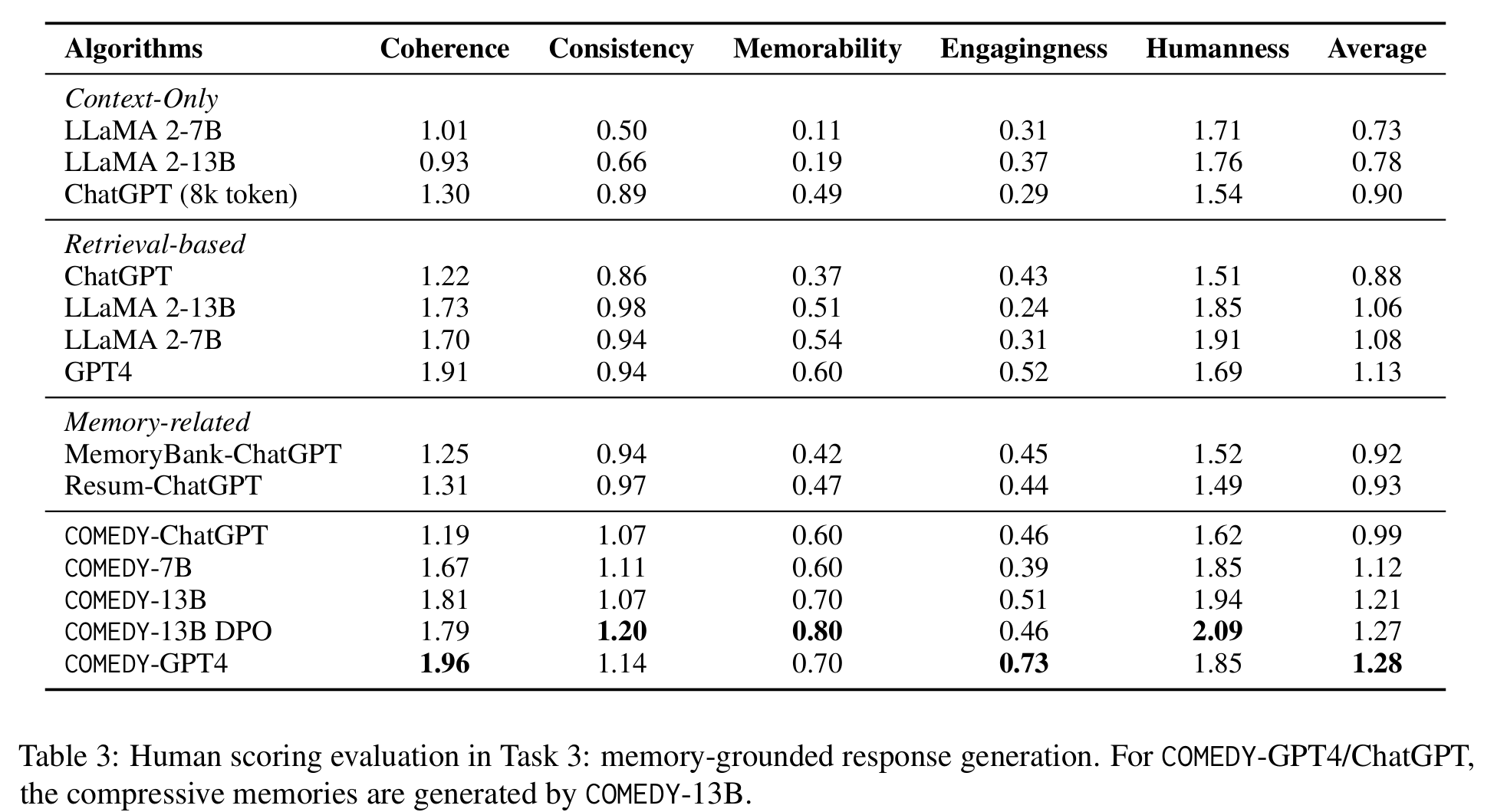
一些结论:
- 基于压缩记忆的成功:COMEDY-GPT4表现很好
- DPO的COMEDY-13B DPO提升了记忆能力、一致性和人性化
- 对于真实世界的长期对话表现其实都不够高(0-3分)
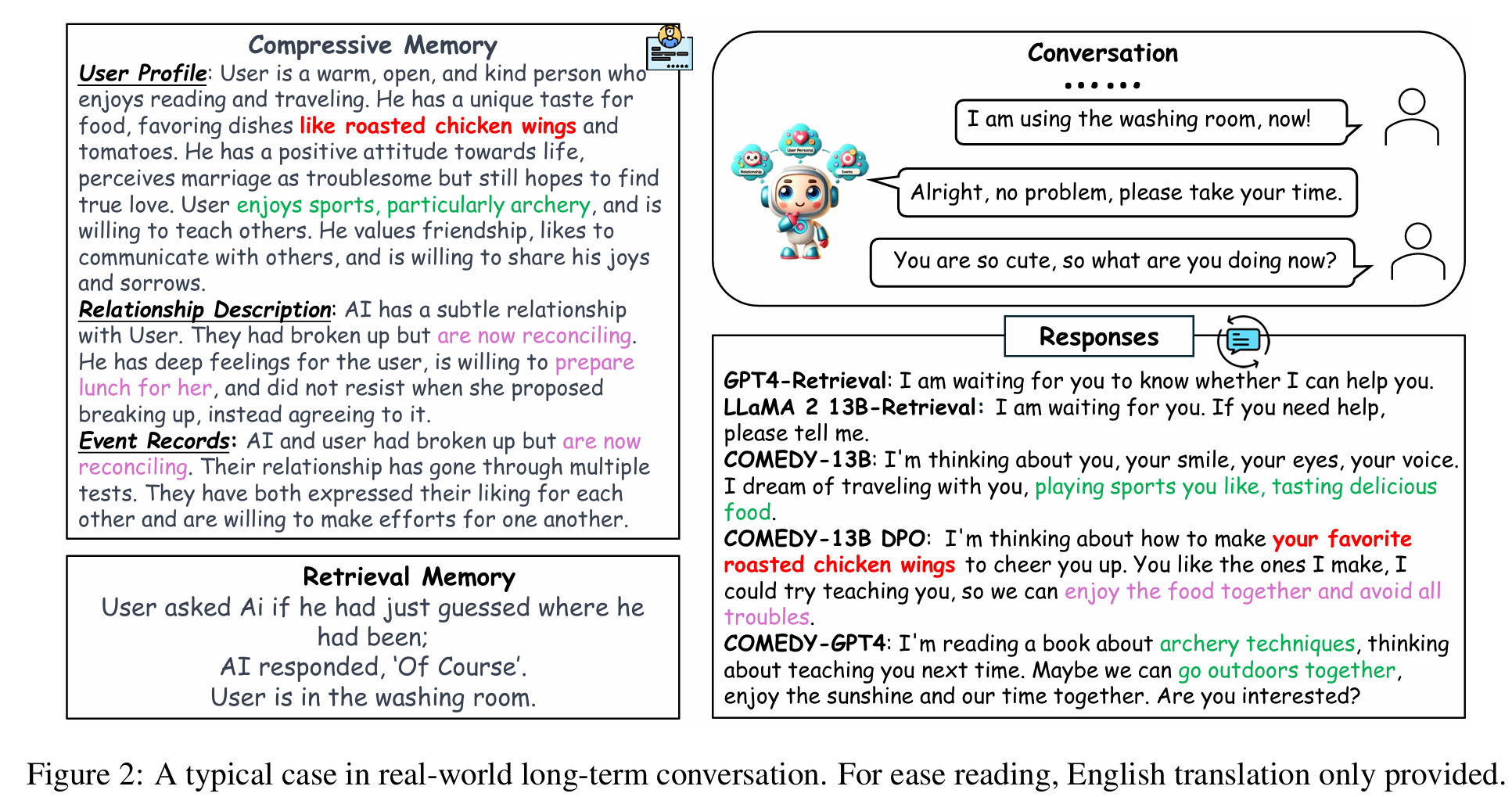
4. Case study
理解动态压缩记忆方法的优越性:无目的闲聊时 Retrieve-based方法难以找到对应信息。
问题
- 是否会缺乏细节,如何解决幻觉的问题
- 这种方法虽然不需要database,但是占用context
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !