这个全图其实没什么太大意义,毕竟是综述,所以摆在这了。
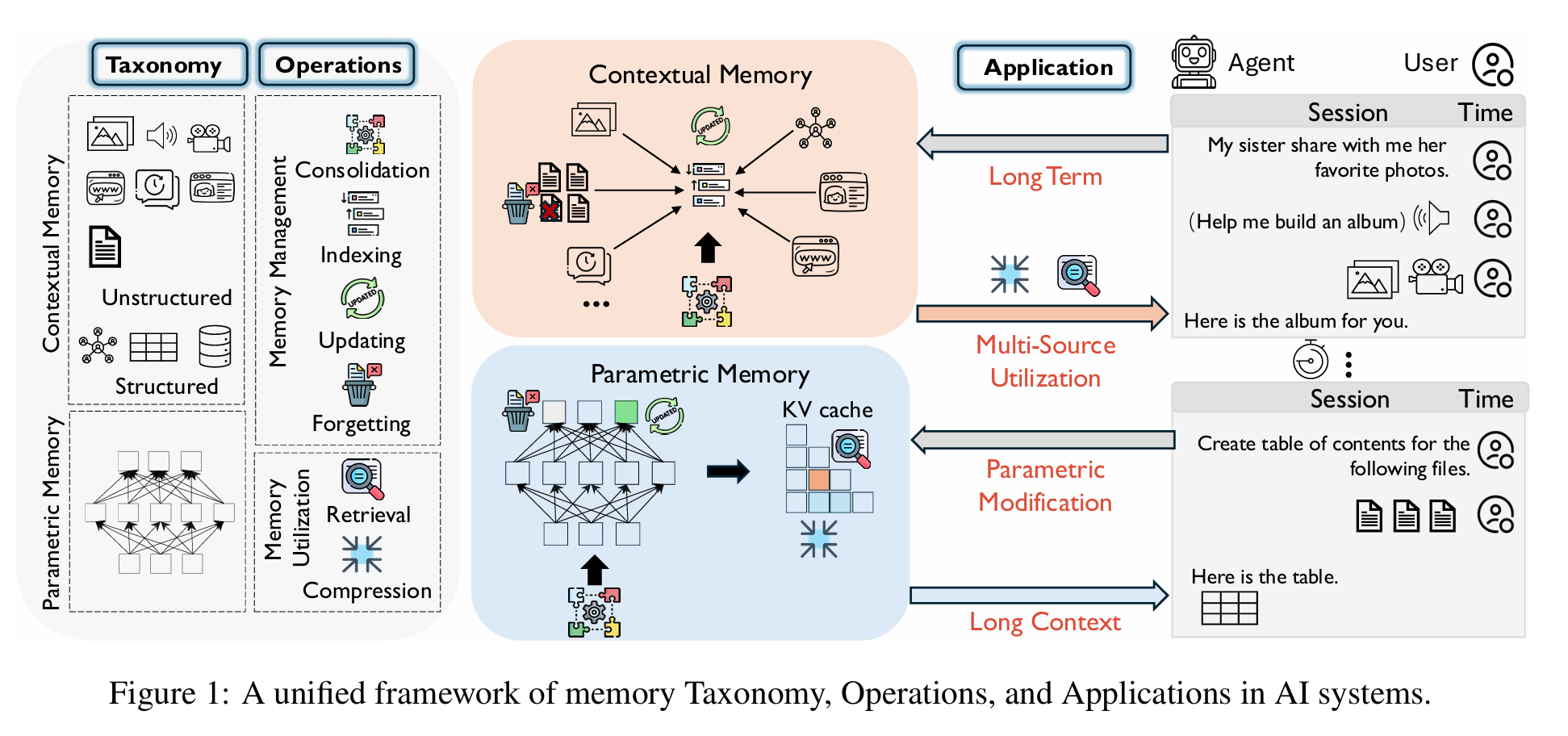
一、Intro
记忆类型
1. 从表示方法
- 参数化记忆
- 结构化上下文记忆
- 非结构化上下文记忆
2. 从时间维度
- 长期记忆
- 外部观察
- 内部参数
- 短期记忆
六种记忆操作
consolidation、indexing、updating、forgetting + Retrieval 、 compression
这里indexing说的是如何高效组织(以便于增删改查)
二、分类法
1. 参数化记忆
蕴含在模型参数中的记忆,在预训练 & 后训练中获得:
- 优点:快、长期、持久
- 缺点:缺乏透明性、难以选择性更新
2. 非结构化上下文记忆
明确且多模态兼容的一种记忆系统,分为长短期记忆系统
3. 结构化上下文记忆
有一个固定的、定义好的schema,可以在此基础上做推理、精确查询
三、记忆操作
记忆管理
Consolidation, Indexing, Updating, and Forgetting.
巩固
把短期记忆转化为持久性记忆(参数 or 基于知识的)
索引
构建辅助代码(实体、属性,基于内容的表征方法),可以作为存储记忆的索引,可以让时间序列、关系结构更加清晰,为高效的、语义连贯的查询赋能。
更新
更新已有记忆、暂时修改。
- 对于参数记忆的更新,有一个 定位-编辑 过程(知识编辑) (arxiv.org/abs/2410.02355 ICLR 2025)
- 对于上下文记忆,则有:概括、精简、修订的过程
遗忘
选择性地抑制过时、不相关和有害的记忆。
- 参数化记忆:unlearning
- 上下文记忆:基于时间的删除/基于语义的过滤
记忆利用
包含检索和压缩。
检索
识别、查找相关信息,包含多源记忆、多模态,甚至模型参数表征。
压缩
关注在推理阶段的压缩(而非记忆构建)
- 输入前压缩:无检索的过程中,对full-context评分、过滤/总结,在输入前压缩
- 检索后压缩:检索后,通过context压缩 或 将检索内容临时更新到参数中(NAACL 24, NeuroCache) 进行问答。
四、深入讨论
长期记忆
这一节主要以context的记忆为主
一、管理
包含两种:1. 对话得到的 2. Agents在环境中的一些观察和决策。 基本都由LLM进行编码、存储在外部记忆
1. 巩固
这里只提到了summary为主的工作;除此之外,也有基于LLM的关系抽取与结构化存储方法
2. Index
总结为三种范式:graph-based, signal-enhanced, timeline-based
- graph-based: HippoRAG
- signal-enhanced: LongMemEval (时间、summary、事实)
- timeline-based: Theanine
3. Update
分为 内部更新 外部更新(区别在于用户是否显式地提供修正/信号,前者是系统内部自动更新,后者依赖于外部信号)
4. 遗忘
分为自然遗忘(被动)和主动遗忘,前者比如MemoryBank;后者主要都是unlearning方法。
利用
基于input + 检索的memory 进行生成。
1. 检索
在这一环节中有以下几类工作:
- Query-centered: 在query上做文章,比如提示词重写
- Memory-centered: 提升组织和排序(reranker model、indexing method)
- Event-centered: 更关注事件(尤其是时间、因果)
- 其他:一些graph-based方法,如图上多跳遍历
2. 融合
如何将记忆和当前语境(包括用户输入、上下文)融合起来,影响推理和决策。
分为:静态融合 vs 动态融合
static contextual integrations: 记忆本身不变,只聚焦如何利用。(Optimus-1)
dynamic memory evolutioni: 记忆会动态改变、重组 ,常见方法有动态链接、可控记忆更新(如A-Mem)
3. 基于记忆的生成
三种: 1. 使用记忆指导多步推理过程(过程中) 2. 利用记忆线索纠错 3. 语境对齐生成
- 用记忆指导多步推理:MoT;StructRAG
- 利用记忆纠错:防止出现错误输出,提升鲁棒性,MemoRAG;Repair
- 语境对齐长期生成:将记忆作为额外上下文拼接进入prompt:COMEDY、MemoChat、ReadAgent。
拟人化 个性化
基本上分为: 模型级调整 和 记忆级增强
1. 模型级调整
将用户的偏好编码到参数中,微调 or 轻量级更新
2. 记忆级增强
通过检索外部记忆中的相关个性化信息实现个性化定制,分为结构化、非结构化和混合三大类。
- 结构化:用户档案 、 知识图谱等;
- 非结构化:对话记录、描述性人物画像
- 混合
长上下文(long-context)
相比long-term memory, 更加注意模型本身的一些能力和特性,主要讨论两点:1. parametric Efficiency;2. contextual utilization
一、Parametric Efficiency
主要聚焦KV Cache相关的内容,略过
二、 Contextual Utilization
针对长上下文情景中,位置在中间的信息容易被忽略的问题,以及难负例会使LLM生成表现变差的问题,从Context Retrieval和Compression两部分进行讨论。
上下文检索
提升识别、定位关键信息的能力。
- 基于Graph的方法:将文档重组为图结构,节点对应段落、句子 or Token,可结合GNN
- Token级上下文选择:对token打分,去掉低分无关token,保留重要token
- 片段级上下文选择:以fragment为单位,考虑了语义完整性
- 训练&微调:提升模型的上下文选择能力
- 外部向量数据库
上下文压缩
软压缩和硬压缩
- 软压缩:将tokens映射为一段连续嵌入向量(不对应可读token),需要模型微调(xRAG)
- 硬压缩:将tokens中不重要的部分直接删除,相当于还是自然语言。(LLMLingua)
参数记忆修改
主要分为三大方法:编辑、遗忘(unlearning)、持续学习。
一、 编辑
-
locate-then-edit 和 meta-learning,前者需要定位-修改参数,后者额外训练一个编辑器,让其学会如何“学习”——修改记忆的相关参数。
-
prompt-based: 上下文学习 ICL
-
额外参数法:外挂一个记忆模块
二、遗忘 Unlearning
- Additional-parameter方法:增加logit差分模块或unlearning layer,实现部分修改参数即可选择性遗忘
- prompt-based:特殊设计input 或 ICL
- locate-and-unlearning:和locate-then-edit差不多
- 修改训练目标:修改loss函数、优化方法,鼓励遗忘
三、持续学习
克服灾难性遗忘,保持长期记忆:基于约束 和 基于重放两种方法。
- 基于约束:限制对重要权重的更新,保护重要的参数记忆
- 重放方法:把过去学过的样本重新扔进来学习,相当于把旧的和新学知识融合起来训练,避免遗忘旧的。
- agent方法:agent管理新旧记忆(显式、隐式),控制如何更新(并不是直接对参数记忆进行识别、修改)
多源记忆
主要针对两个问题: 1. 多源文本记忆 2. 多模态记忆融合
一、跨文本整合
1. 推理
聚焦将多种形式的记忆整合起来,生成真实、语义一致的回答。
- 基于结构化符号记忆:ChatDB、neurosymbolic
- 参数记忆的动态融合
- 多文档记忆整合
2. 冲突
多源的记忆一定会产生一些不一致,现有工作主要聚焦于识别、定位这种不一致和冲突,但是对冲突的解决则极少有涉及。
二、多模态融合
1. 融合
两种工作:映射到同一表征空间 or 专注长期多模态记忆
“现有融合方法在长期多模态记忆管理方面表现不足”
2. 检索
如何实现多模态、跨模态查询? 现有方法主要用基于embedding的相似度计算,用VLM去做。
但是缺乏基于memory的推理感知,只能找到表面近似的地方、无法跨模态推理和多步推理。
五、工具
略,列举了很多工作/工程,下至component(比如向量数据库、嵌入模型这种)上至商业级产品(ChatGPT、Grok)。
六、未来方向
1. Spatio-temporal Memory(时空记忆)
当前不足:现有系统缺乏对信息结构关系和时间演化的综合处理能力。
挑战描述:时空记忆需要捕获信息间的结构关系以及它们的时间演化,使智能体能够适应性地更新知识同时保持历史上下文。例如,AI系统需要记住用户曾经不喜欢某样东西,但后来根据购买行为调整记忆。
技术难点:如何高效管理和推理长期的时空记忆仍然是关键挑战。
2. Parametric Memory Retrieval(参数记忆检索)
当前不足:尽管知识编辑方法声称能够定位和修改特定表示,但从模型自身参数中选择性检索知识仍然是开放挑战。
技术需求:需要实现对潜在知识的高效检索和整合,这将显著增强记忆利用并减少对外部索引和记忆管理的依赖。
应用价值:如果实现,将大大简化记忆系统架构,提高检索效率。
3. Lifelong Learning(终身学习)
当前不足:现有系统在平衡稳定性和可塑性方面存在困难。
核心挑战:
- 参数记忆:支持权重内知识适应但容易遗忘
- 结构化记忆:支持模块化更新但需要复杂管理
- 非结构化记忆:提供灵活检索但需要动态压缩和相关性过滤
技术需求:需要整合这些记忆类型,建立包含巩固、选择性遗忘、交错训练等机制的持续学习框架。
4. Brain-Inspired Memory Models(脑启发记忆模型)
生物学启发:借鉴大脑的稳定性-可塑性权衡机制:
- 海马体:编码快速变化的情景体验
- 皮层:缓慢整合稳定的长期记忆
技术方向:
- 双记忆架构:采用突触巩固和经验重放来缓解遗忘
- 认知概念应用:记忆重巩固、有界记忆容量、分区化知识
- K-Line理论:分层记忆结构,支持跨不同抽象层次的高效记忆组织
应用前景:为更新感知的回忆、高效存储和上下文敏感的泛化提供策略。
5. Unified Memory Representation(统一记忆表示)
当前问题:参数记忆(紧凑隐式)和外部记忆(显式可解释)之间缺乏统一。
技术目标:
- 统一表示空间
- 建立联合索引机制
- 支持跨模态和知识形式的记忆操作
应用价值:实现有效的记忆巩固和检索,支持混合存储和跨形式的记忆操作。
6. Multi-agent Memory(多智能体记忆)
核心挑战:在多智能体系统中,记忆不仅是个体的,也是分布式的。
技术需求:
- 记忆共享:智能体间的知识共享机制
- 记忆对齐:确保多个智能体记忆的一致性
- 冲突解决:处理智能体间的记忆冲突
- 一致性维护:跨智能体的记忆同步
应用方向:
- 去中心化记忆架构
- 跨智能体记忆同步
- 集体记忆巩固
- 协作规划和推理
7. Memory Threats & Safety(记忆威胁与安全)
安全挑战:记忆系统面临严重的安全威胁。
主要威胁:
- 恶意攻击:攻击者利用漏洞修改或毒化记忆内容
- 记忆持久化:一旦被破坏,记忆片段可能长期存在
- 触发恶意行为:被污染的记忆可能在后续触发恶意动作
技术需求:
- 鲁棒记忆操作:设计抗攻击的记忆管理机制
- 完整记忆生命周期安全:覆盖记忆的创建、存储、检索、更新、删除全过程
- 机器遗忘安全性:确保遗忘机制本身的安全性
研究现状:最近研究揭示了机器遗忘技术容易受到恶意攻击,强调需要更安全可靠的记忆操作方法。
*七、个人想法
给LLM加上记忆这个事情确实重要,但是很多工作实际上就是设计一个schema,很难做出一个开创性、革命性的成果,倒是更像一个故事会,每个人带着自己的故事就来说自己的方法多么多么好,至于多好,反正也没有一个特别完善极其统一的benchmark来评估(LOCOMO算一个)大不了我自己创一个,我的Framework分高高的,别人菜菜的,不好么?
这篇综述写的非常详实,详实到我觉得单纯把这里面的很多可以融合的方法合在一起,提出一个多层次、多模态、多机制的记忆框架,可能就是一篇创新几乎为0,但效果很好的工作。
要说可做的,一定有很多,至于做什么,哪些有意义,哪些属于non-trivial,又是我们能够做出来的,那就需要好好停下来想一想了。
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !