Retrieval-Augmented Perception: High-Resolution Image Perception Meets Visual RAG
0. Brief takeways
对于多模态大语言模型MLLMs对高分辨率图像感知HR image perception任务中,利用类似RAG的方法实现。
方法: Crops分块 + VisRAG确定余弦相似度s + Spatial-Awareness layout 保留位置关系,然后不被选中位置留空,删除全空行和列 + RE-search(类A*) 确定最优的topk 。
1. Intro & Related work
MLLM现在对图像的处理,大多都是fixed resolution。如果处理高分辨率图像,会面临shape distortion、blurring的问题。
现在基本上有三类方法:cropped based,HR visual encoder,search based。
前两种不可避免下采样,丢失细节。
第三个也有一些问题:采用的top-down搜索方法,先不下采样,分块查询(貌似是这样,有待确认),但是小物体(或者特征不是那么明显)的感知就容易在前段直接出错了。
作者认为要想提升HR image的感知能力,最好能实现MLLM的长上下文能力——于是想到了RAG,于是提出了本文的核心问题:
Is it possible to directly enhance the long-context capability of MLLMs using RAG, as in general LLMs, to overcome the limitations of existing HR perception methods?
随之而来的两个关键问题:切成小块以后这些图片怎么摆?要用多少个crops?
小结论
1. 怎么排RAG后的crop结果最好?
三种方法:1. 按相关度高低顺序 2. 按原始顺序(这个是哪里的原始顺序?) 3. 保留他们的相对位置关系(how?)
结论:方法3最好
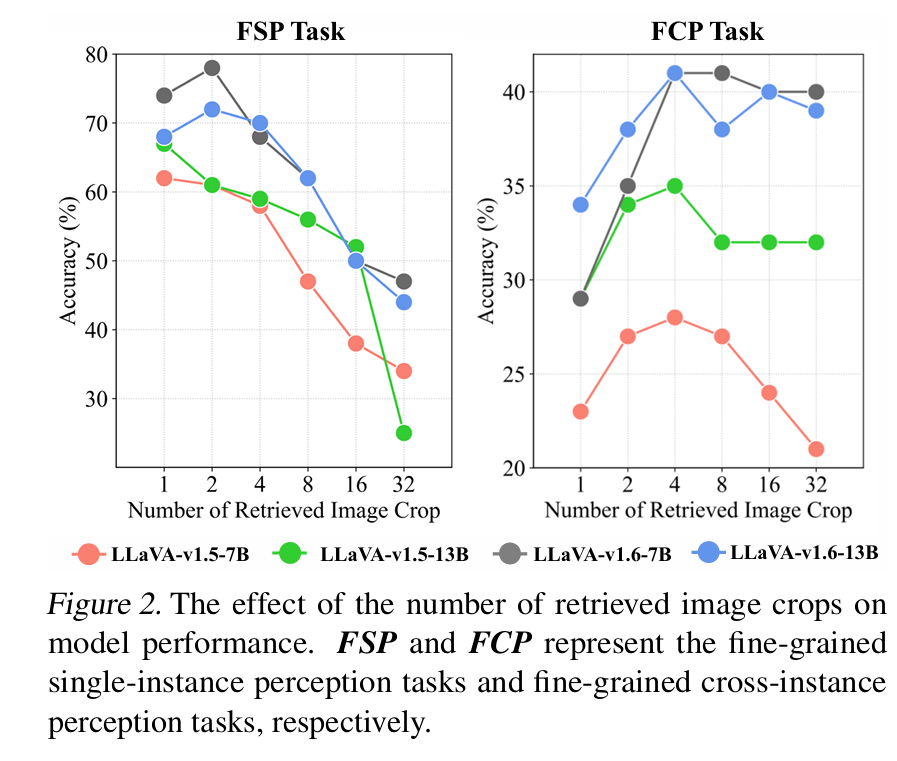
2. 多少个crops好?
和task有关
对于单图任务,小数目即可,多了可能反而差
对于跨图片感知:中等数目,不高不低最合适。
3. 如何设计一个RAG系统,用来提升MLLM对HR image的perception?
提出 Retrieval-Augmented Perception(RAP) 框架。
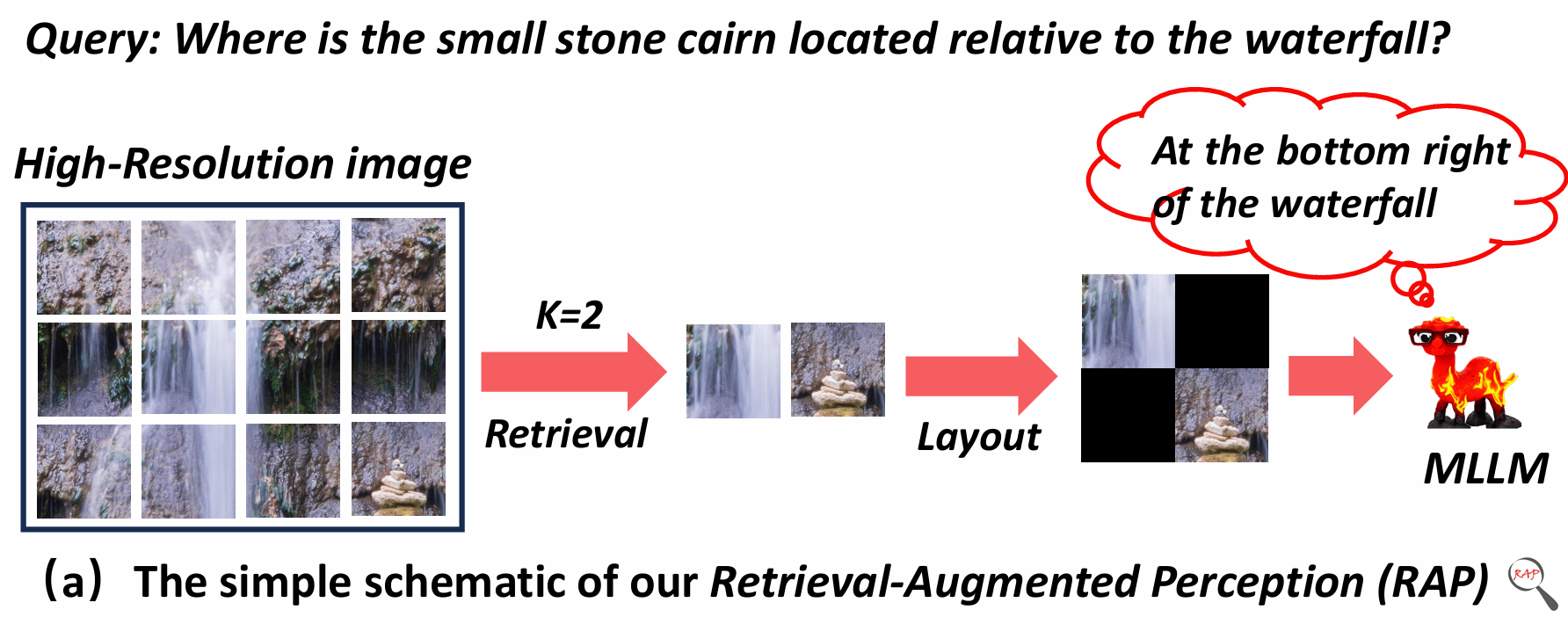
具体来说:VisRAG计算query和图片相似度 + Spatial-Awareness Layout(本文提出)+ RE-search(确定number)
VisRAG topk —— S-A Layout —— Construct RE-Tree —— search on Tree
贡献
- 第一个用RAG 增强MLLM 的HR image 感知,并强调保持原来的相对位置关系以及对crops数目的探索
- RAP框架,training free,包含Spatial-Awareness Layout和RE-search
- 实验结果:HR image benchmark上平均24%提升,general MLLM benchmark也有提升。
pre Research
1. 相似度
图像V分块,然后用余弦相似度计算分数:
$$
s(q,V)=(1-\frac{q\cdot V^T}{||q||\cdot ||V||})\cdot \frac{1}{2}
$$
2. Layout方法
按分数、按crops在原来分块后crops中的序号(我理解是这样)、保持相对位置关系(这个到底怎么实现)
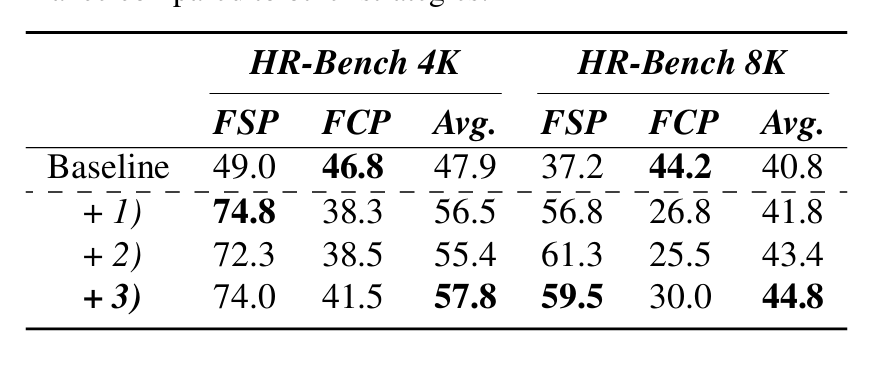
结果: 在 LLaVA-v1.6-7B + HR-Bench上,出现了FSP(fine-grained single-instance perception)表现大幅提升,但是FCP(cross-instance) 明显下滑,三者之中表现最好的是方法3。
原文下一个section详细介绍了怎么实现这个保持相对位置关系,就是设了一个01矩阵M,1表示保留,实际上就是s比较大的会被保留,然后把全0行和全0列全删了,留下一个新的矩形图片。
3. 使用的数量
LLaVA-v1.5 、 LLaVA-v1.6 的7B和13B,一共四个模型。
看起来用的是HR-Bench 4k
很神奇的是,他只有1.6的版本有出现FSP的先提升后下降,尤其是这个拐点,为什么不做一组Num=3的呢。
4. RE-search
用来找出最优的k(喂给MLLM crop的数量),现有搜索方法要么低效(全部遍历)、要么不够robust(蒙特卡洛)
这里基于A*的启发式搜索算法,给出他们的RE-search。
A*算法中的g函数和h函数,在这里被定义为了平均相似度和 不确定度,然后用一个随着depth增加而增加的w(因为最开始搜索出来的)来分配权重。
$$
f(t_s)=(1-w)\cdot g(t_s)+w\cdot h(t_s)\
w=(1-b)\cdot(1-\frac{1}{d})^2+b~~~(b=0.2 ~here)\
g(t_s)=\frac{1}{n}\sum_{i=1}^{n}s(q,v_i)\
h(t_s)=1-P_{\theta}(‘YES’|p_h(q),V)
$$
实验
benchmark
质疑
- 如果对应的内容在原始HR图片中被crop成了多个块,怎么办呢。
- LLaVA
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !