CS 285 DRL notes
Basic Terminologies
s state
o observation, important parts of a state (things that we concern)
a action.
$\pi$ refers to a policy, which is just what the RL algorithm can gain after learning. $\pi_{\theta}$ is the policy learned from data and $\theta$ refers to parameters in the policy.
The subscript t (such as $s_t, o_t, a_t$) is a time stamp.
Imitation Learning
Just imitate what the machine “see” , which usually refers to experts’ behaviors or actions from training data.
Problem
Because of a tiny wrong caused by the learned policy $\pi_{\theta}$, it may be in a brand-new state that has never occurred during the training process. This may lead to a worse action and accumulate the error.
What’s more, the i.i.d. condition can’t be meet, which is just the Distribution shift problem. The distribution in training dataset is different from the dataset in test. Such as a autonomous driving program, trained in good weather but tested in rainy or foggy situations.
Analysis
Some keys:
- Cost function: action same with experts behavior -> 0, otherwise ->1
- Assumption: the supervised learning works well: for s appeared in $D_{train}$, $E \leq \epsilon$.
- Once the model responds with a wrong action, which may make the state unfamiliar and unable to mitigate. So the cost will be $1 \times T$ (T for time span from now to the end)

In the slide, prof shows us the evaluation of the upper bound of E(cost). It is clear that as the T goes longer, the error will be increasing in a non-linear way, which is bad.
Solution
1. Intentionally add mistakes and corrections
This may dilute the dataset, but the benefit will be larger.
2. Data augmentation
Nvdia’s autonomous driving with two side cameras.
3. Using historical data
In some circumstances, one reason that produces bad performance is the non-Markovian behavior. Human experts don’t make decision only based on the current state, but also what you have experienced or what you have seen before.
E.P. when you are driving, a car disappeared in your vision but you may know it is in your blind spot now because in last few seconds you can see it from your rearview mirror. But if you just judge from the current state, you will not know this information.
Using historical data may cause Causal confusion. Machine will consider that you should break when the car is slowing down but actually it is that you break when you find a person few meters in front of the car and you break.
4. Expressive continuous distributions
For multi-model problems.
Mixed Gaussian, latent variable models, diffusion models
Discretization.
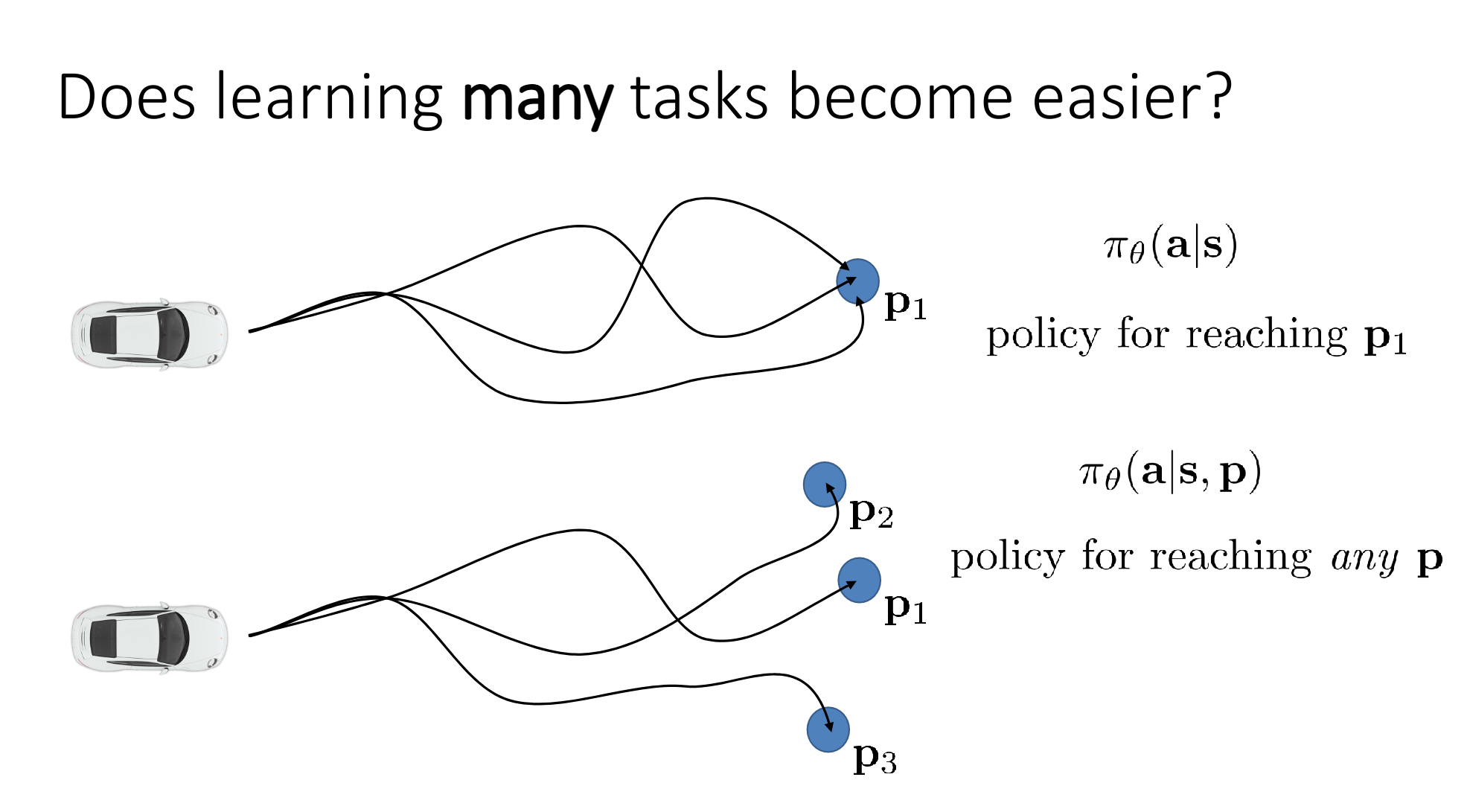
5. Multi-task learning
Different goals, but learn together.
For example, several experts drive to different places, the machine learn all of them even though its final goal is to arrive just one of the target.
6. Relabeling method
Not fully understand yet. I regard it as a way to make the machine understand that the goal of this data may not be the one you want (in the context of imitation learning?)
7. DAgger
Dataset Aggregation, trying to collect dataset from real p ($p_{\pi_\theta}(\bold{o_t})$)
Running the policy, get data $D_{\pi}$, ask human to label Data with their Action, Aggregate $D_{\pi}$ into D
Restrictions
- Unnatural for human to label.
- Unable for human to label.
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !