LLM Memory (for chatbot)相关工作整理
〇、Introduction
LLM的爆火已不必多说,但LLM在当前阶段,仍然存在着上下文窗口有限的问题。在chatbot等场景中,为了让对话保持自然,让LLM保持对话记忆尤为重要。
把最近的聊天和对话尽可能放进上下文窗口,是一个之前比较通用的做法,很明显,这不仅受到上下文限制,同时也难以解决跨session、长期记忆遗忘的问题。
最朴素的RAG是一个思路,但是他不够好,具体来说,体现在这一场景下有几个比较明显的特征:话题不一、聊天可能出现比较不明确的指代,需要语境信息进行综合理解,难以被简单的检索。
因此,出现了各种方法来给LLM设计一个记忆的机制或模块。具体来说,我认为主要有三个部分:(1) 记忆的生成/提取 (2) 记忆的存储与管理 (3) 记忆的检索和提取利用。 他们分别解决了存什么、怎么存和怎么取用这三大问题。
从存储内容和方式的角度来看,可以主要分为:turn-level、session-level、summary,以及后来提出的动态粒度四个方面。
一、 工作梳理
1. MemoryBank
创新性地引入了艾宾浩斯遗忘曲线理论,以此模拟人类的记忆更新、遗忘、强化机制。
这种方法也经常被用来当做后面工作实验部分的Baseline。
2. LD-Agent
Hello Again! LLM-powered Personalized Agent for Long-term Dialogue
arxiv 2406.05925
3. SeCOM
On Memory Construction and Retrieval for Personalized Conversational Agents
ICLR 2025 清华+微软
主要贡献:
-
研究了不同粒度下构建记忆面临的问题
-
提出SECOM系统,在Session中以话题为单位进行记忆存储。主要由 对话分割model + compression based denoising两部分组成
Topic-based segmentation
摒弃传统的Turn-level、Session-level或基于Summary的记忆存取方法,提出以topic为依据的“段”划分方法。
在某一Session中,如果话题发生变化,则从这两条之间切一刀分成两段。每段记忆存储一个 (开始, 结束) 对,形式如下:
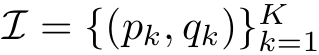
用GPT-4分割(也验证了Mistral-7B和RoBERTa)。
并提出使用少量标注数据提升分割效果的类CoT方法:让LLM找到分段效果最差的一些难例,跟ground-truth进行比较,生成反思或提示,放进下一轮的Prompt。
Memory unit denoising
一些冗余或无意义的表达类似噪声,采用LLMLingua2(arxiv.org/abs/2403.12968)的压缩方式,将retrieve出来的记忆单元逐个压缩。作为Prompt的一部分。
实验


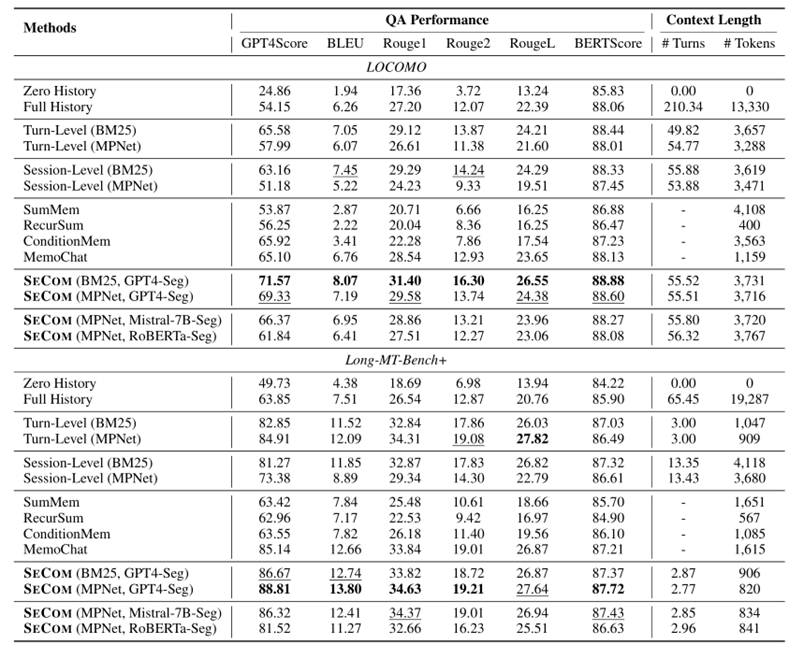
消融实验

评价
-
找到了一个更具有语义性的动态粒度。
-
没有提及对记忆进行动态的更新、删除,只说了按段分割、存储,然后做retrieve。
-
按段分割,会把A-B-A-B-A划分成五段,没有一个合并的过程。可能是一种效率和表现的权衡。
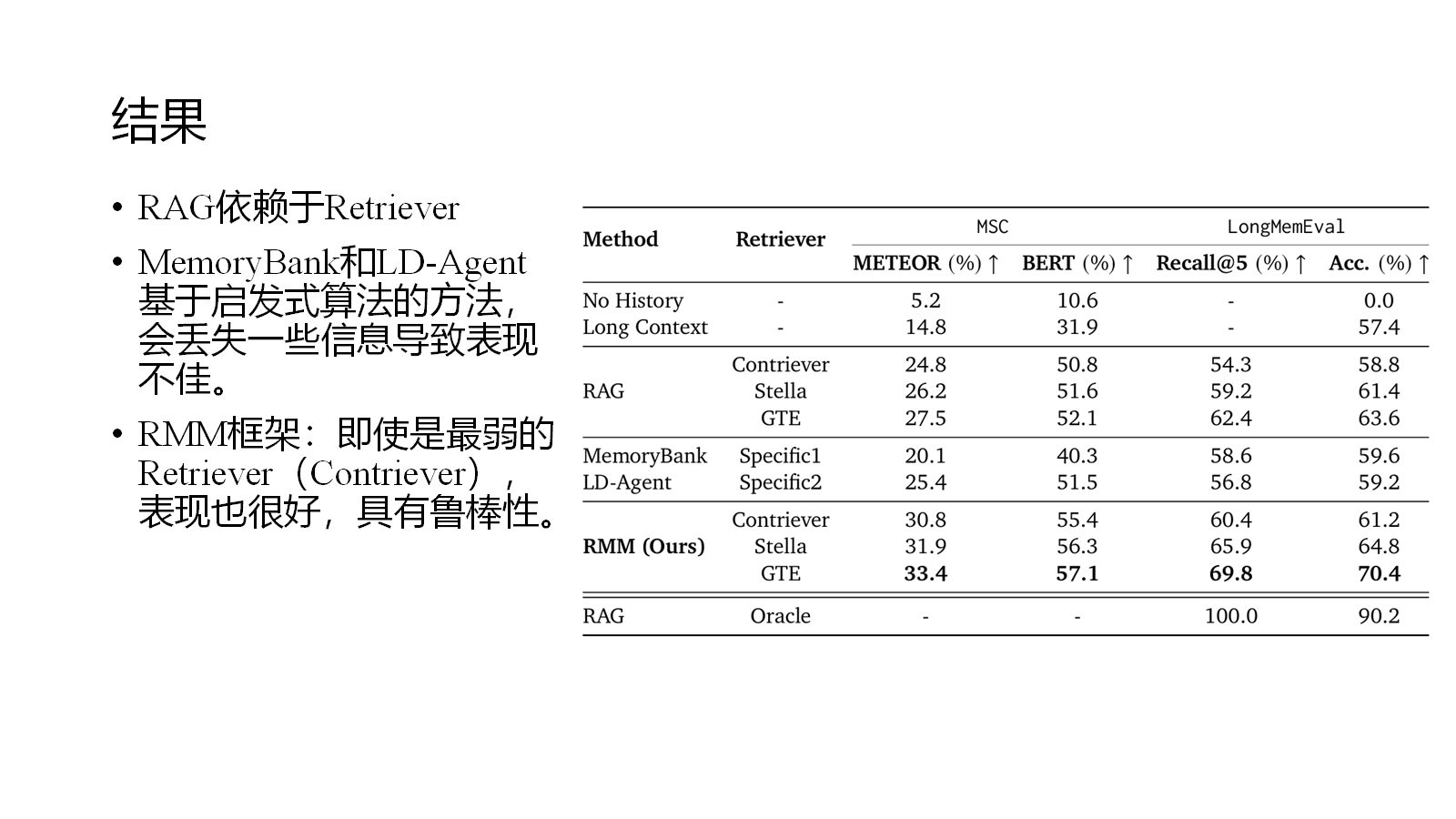
4. RMM
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents
arxiv.org/abs/2503.08026 Google Cloud
主要贡献:
-
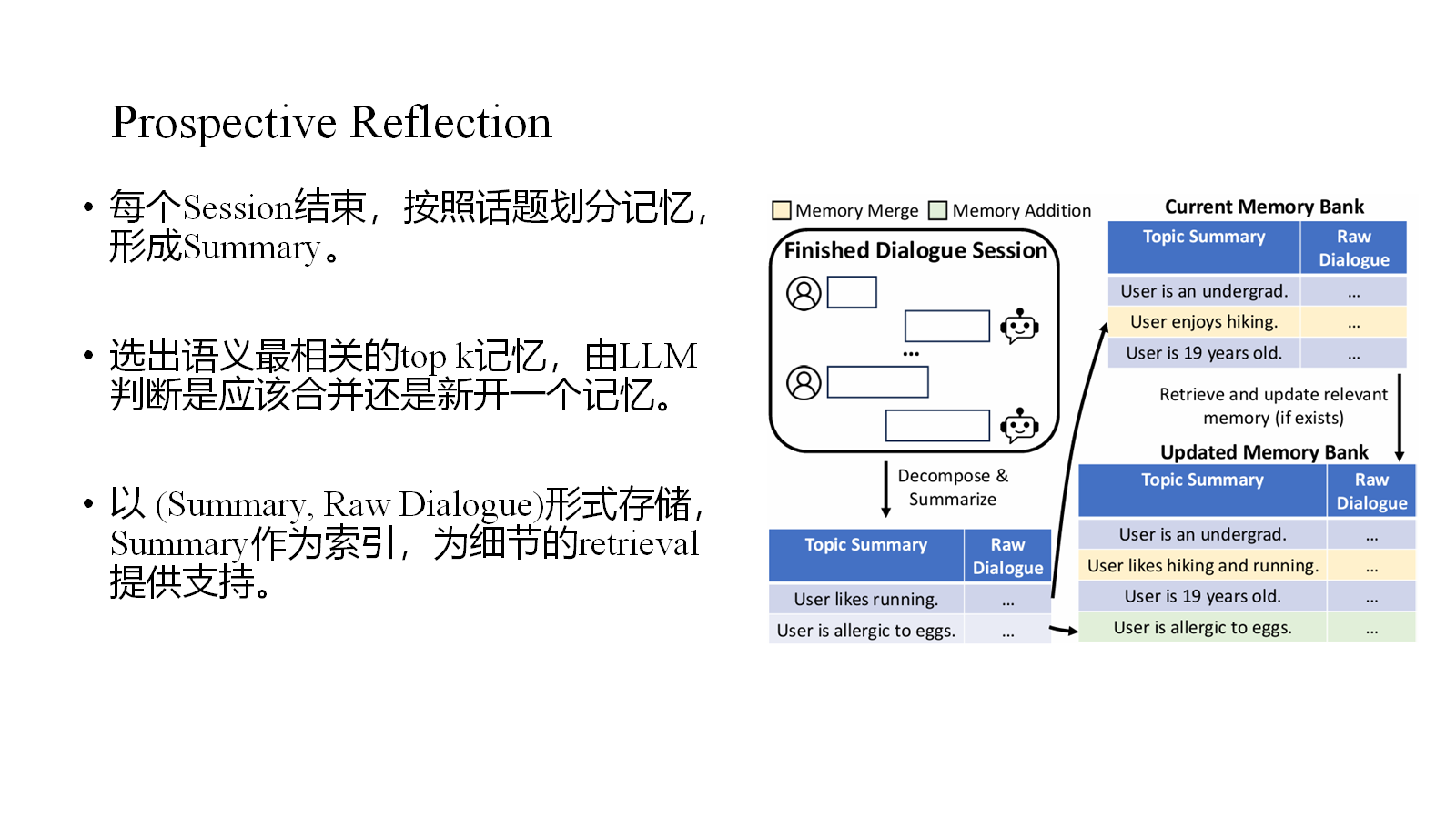
提出RMM架构,由Prospective Reflection和Retrospective Reflection组成。
-
Prospective Reflection采用topic-based方法,也有对记忆的更新机制
-
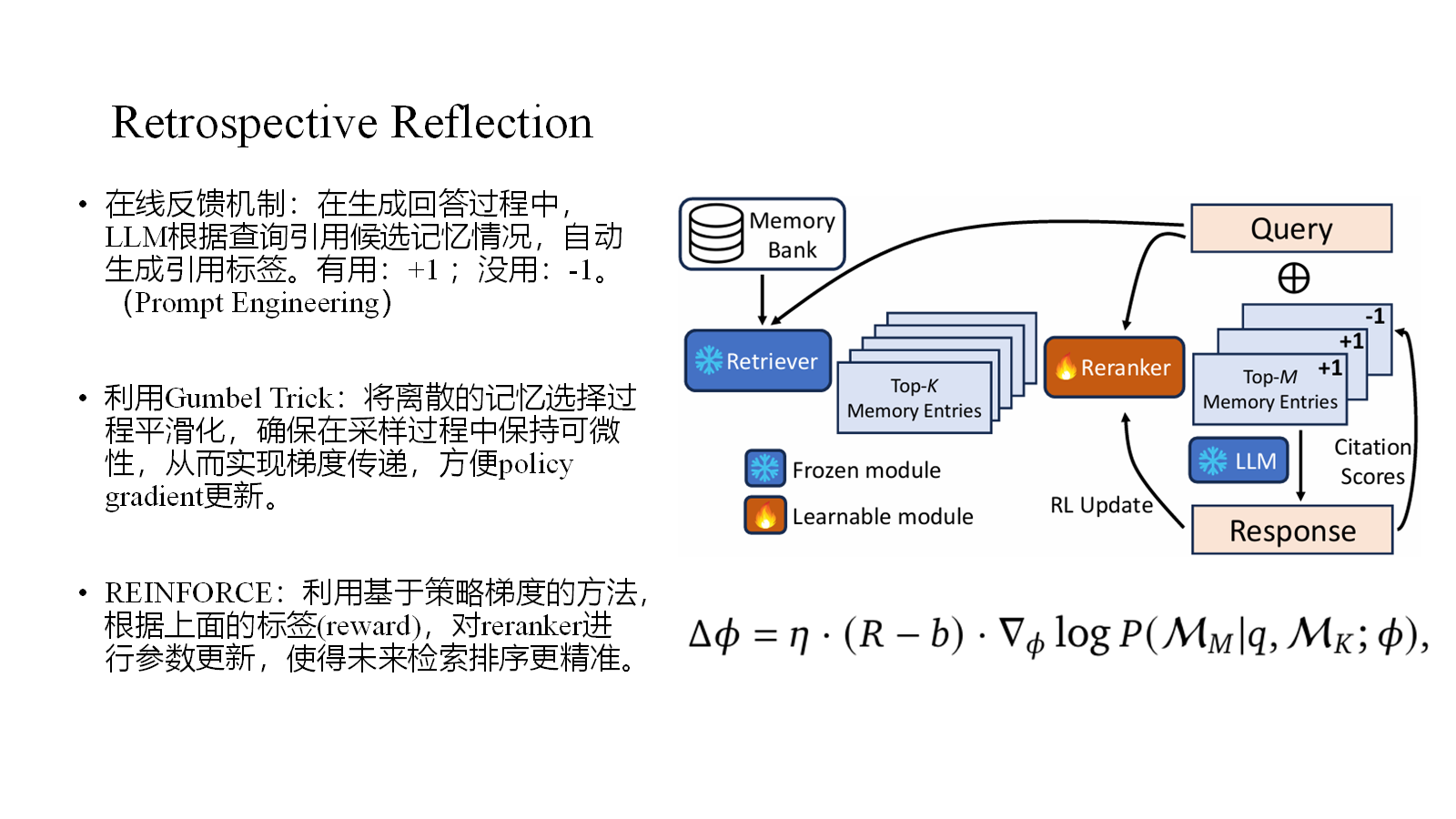
Retrospective Reflection使用可训练的reranker,以LLM对retrieval信息的使用情况作为反馈信号,实现基于策略梯度的reranker参数更新。
评价:
-
同样是topic-based方法,相比上一个工作更加细致。
-
创新性引入了RL的方法,动态优化检索效果。
-
索引式存储记忆能够提供很好的细节支撑。


5. MemInsight
6. MemGPT
7. Mem0
来源于优秀开源项目(接近3w stars)
8. Zep
二、 相关Benchmark
LOCOMO
ACL 24
https://github.com/snap-research/locomo QA & 事件摘要 & 多模态对话生成
LongMemEval
(ICLR 25) https://github.com/xiaowu0162/LongMemEval
MSC
https://arxiv.org/abs/2107.07567
DMR
Deep Memory Retrieval,MemGPT提出的,被Zep用来对比测评
https://arxiv.org/abs/2310.08560
三、SOTA
整理一下现在的工作:
SeCOM、MemInsight
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !