1. On Memory Construction and Retrieval for Personalized Conversational Agents
ICLR 2025
https://arxiv.org/abs/2502.05589
清华 + 微软
Brief takeaway
- 研究了不同粒度下记忆构建的问题(Session-level、turn-level、summary)
- 提出SECOM,包含一个对话分割model + compression based denoising(LLMLingua2)
分割模型
直接用GPT4(也尝试了Mistral-7B、RoBERTa进行验证)。同时提出类似CoT的方法利用小范围标注数据提升分割能力和质量。
对一批样本进行分割,然后对效果最差的和标注例进行对比反思,生成一个改进建议指导模型下次分割。
具体分割方法:
一个session的对话Sequence,按照话题从中间直接分段,以段为一个记忆粒度。
实验与结果
生成模型:GPT-3.5-Turbo(也做了Mistral-7B-instruct的鲁棒测试)
**metrics:**BLEU、ROUGE、BERTScore,以及一个基于GPT4输出的GPT4Score;也有一个GPT4进行偏好选择(两个答案之间对比)的过程和人类评估。
baseline:四种原始方法和四种SOTA模型。(1) turn-level (2) session-level (3) Zero history (4) Full History (5) SumMem (6) RecurSum (7) ConditionMem (8) MemoChat
benchmark:LOCOMO、Long-MT-Bench+(从MT-Bench+构建)
结果:
- SECOM比所有baseline都好,尤其是在LOCOMO。
- 观察到Turn level和Session level在使用不同retrieval model的时候差别很大,而SECOM则有较强鲁棒性。归因于:根据话题进行分段,在尝试包含更多有效信息、排除无关信息的过程中能够表现更好。
- summary based方法表现不如turn或者session level,有可能是由于丢失了关键的细节。
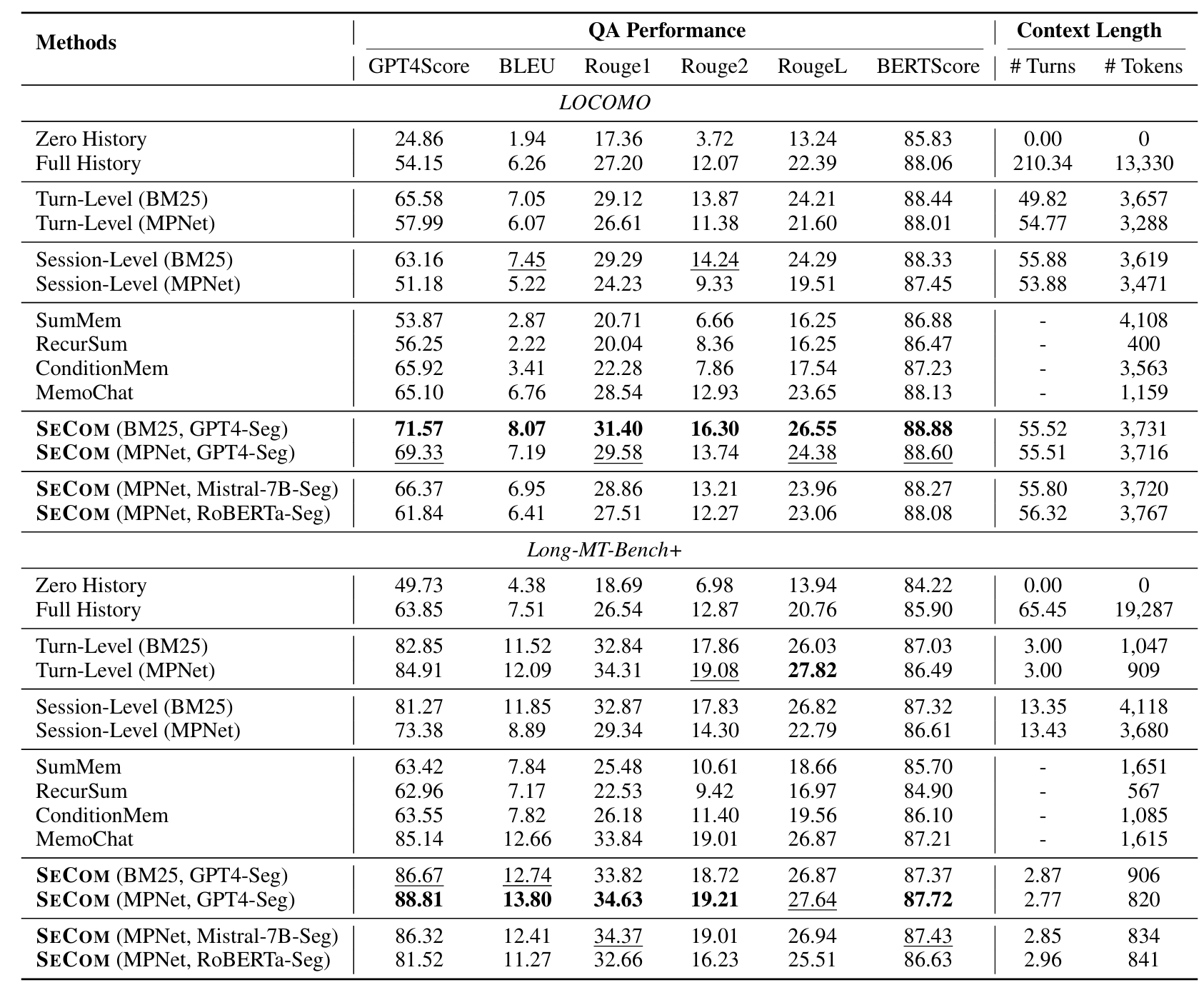
消融实验
1. 变化retrieval长度时,不同粒度的表现
用的是Long-MT-bench+
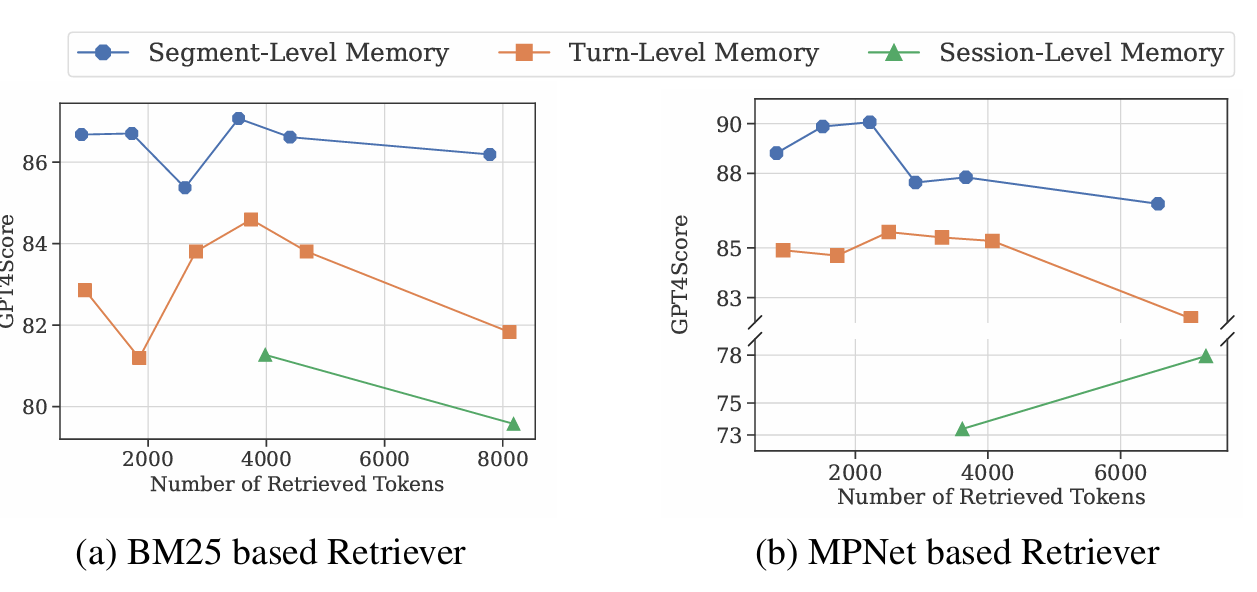
2. 压缩方法
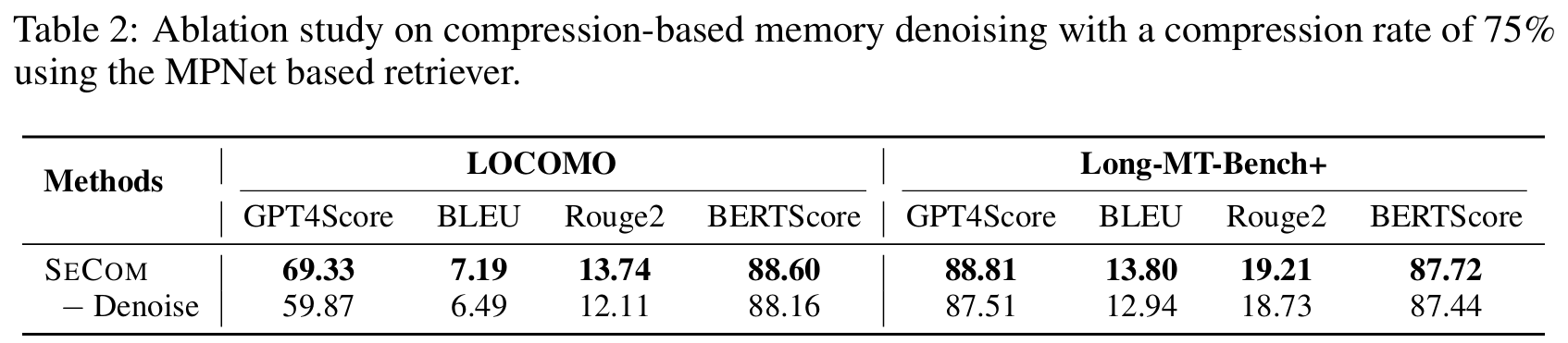
3. 生成模型
用了Mistral-7B-instruct
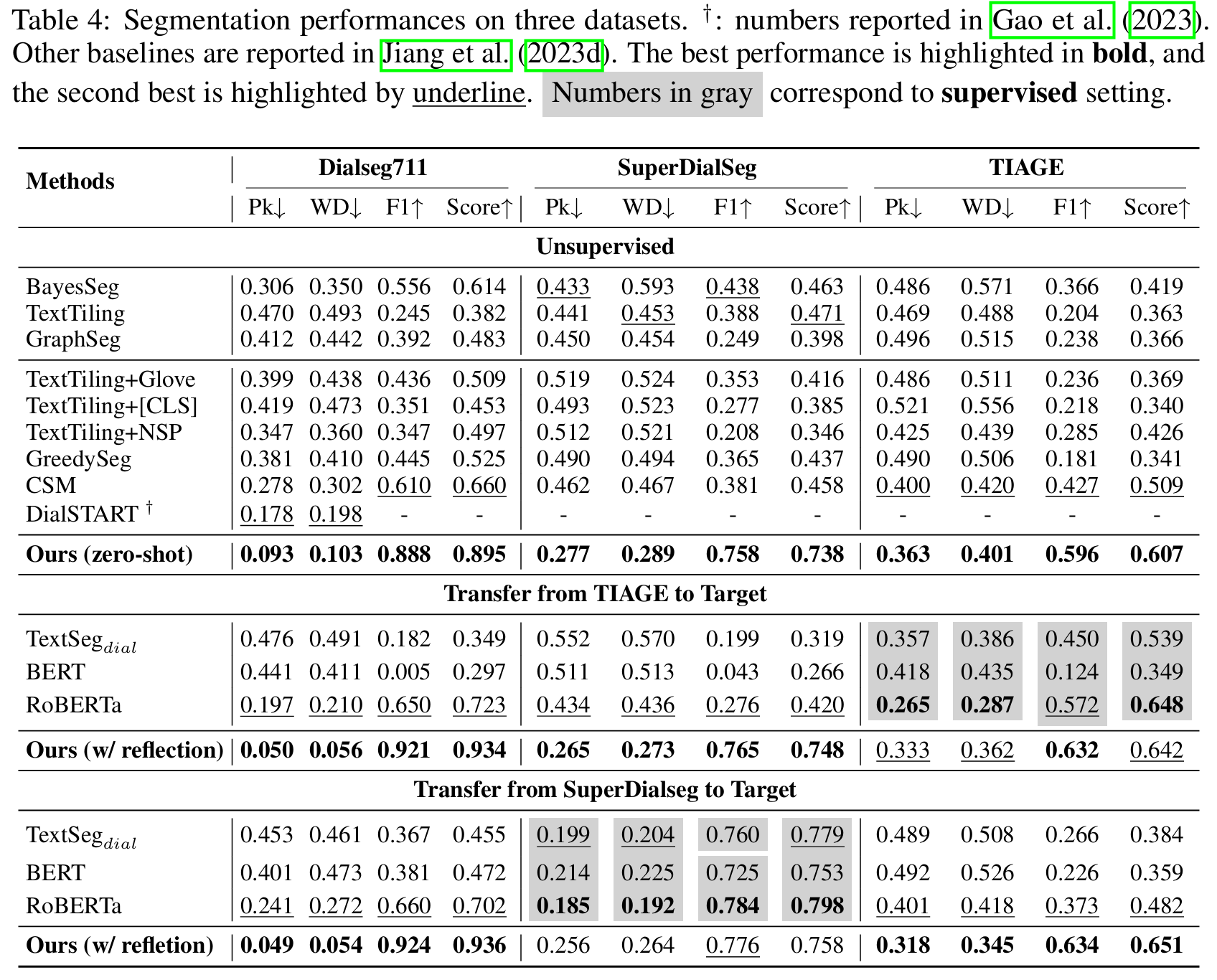
4. 单独对分割model的测试
baseline:其他各种分割模型
包括Zero-shot、和迁移学习。
迁移学习:其他baseline学习完整数据集,SeCOM根据之前的反思方法学习top100难例。
dataset:对话分割数据集DialSeg711、TIAGE、SuperDialSeg
Score:综合F1、Pk(一个在固定窗口下比较分割错误,最终计算得到分割错误的概率)、WD(WindowDiff)
$$
Score=\frac{2\times F1 + (1-P_K)+(1-WD)}4{}
$$
总结和疑问
实际上可以总结为:
- 提出按照话题对Session内,根据话题进行分割。找到了Session-level和Turn-level之间的一个动态可变的存储粒度
- 使用LLMLingua2进行去噪压缩,用来去除一些自然语言中重复冗余的表达和内容。
问题:
- 没有对记忆进行动态的更新、删除,只说了按段分割、存储,然后做retrieve。
- 按段分割,会把A-B-A-B-A划分成五段,没有一个合并的过程。可能是一种效率和表现的权衡。
2. SHARE: Shared Memory-Aware Open-Domain Long-Term Dialogue Dataset Constructed from Movie Script
韩国西江大学
Brief takeaway
- 构建了基于电影脚本的数据集SHARE,通过GPT自动标注,包括双方persona、共享记忆Shared memory
- 提出了一个EPISODE Framework:包括记忆生成(每个session结束后生成)、更新(因果顺序连接、冲突则更新)的管理模块,以及生成模块。
方法
主要介绍EPISODE Framework,包含:
-
记忆选择模块:基于LLaMA 3训练一个selector,从记忆库选择相关记忆,或者“EveryDay language”即不选记忆。训练数据由GPT4o标注。
-
记忆管理:
a. 信息抽取:又一个LLaMA 3 模型,用制作SHARE数据集过程中的信息训练
b. 记忆更新:判断是否相关,独立的就新增(互动的就记入共享记忆);存在因果、时间顺序的就更新;修改冲突内容;不存重复内容。
-
生成:LLaMA/Gemma
实验结果
基础模型:Gemma 2B、LLaMA-3-instruct 8B。
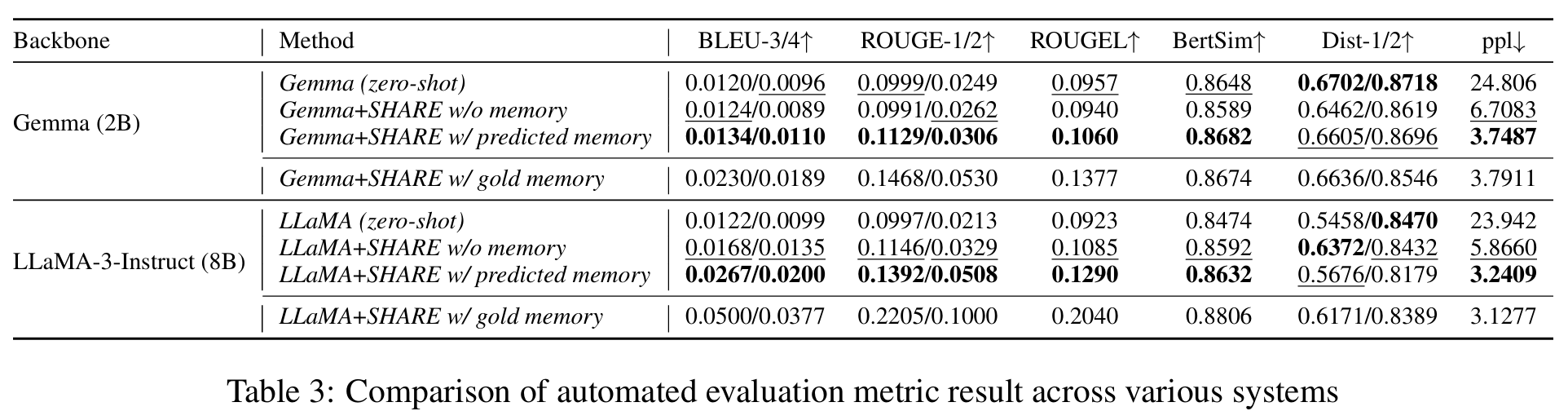
1. Memory 提取与利用
对照:zero shot、no memory、predicted memory、gold memory
分别代表:原始模型;只用SHARE对话而不用记忆微调的模型;用记忆提取器得到的predicted memory辅助生成;用SHARE数据集中标注好的、代表高质量memory的记忆生成。
指标:常见自动化指标 BLEU、ROUGE、BERTScore、Distinct、PPL
结果:
- predicted memory虽然无法达到gold memory水平,但是相比without memory,有很大提升
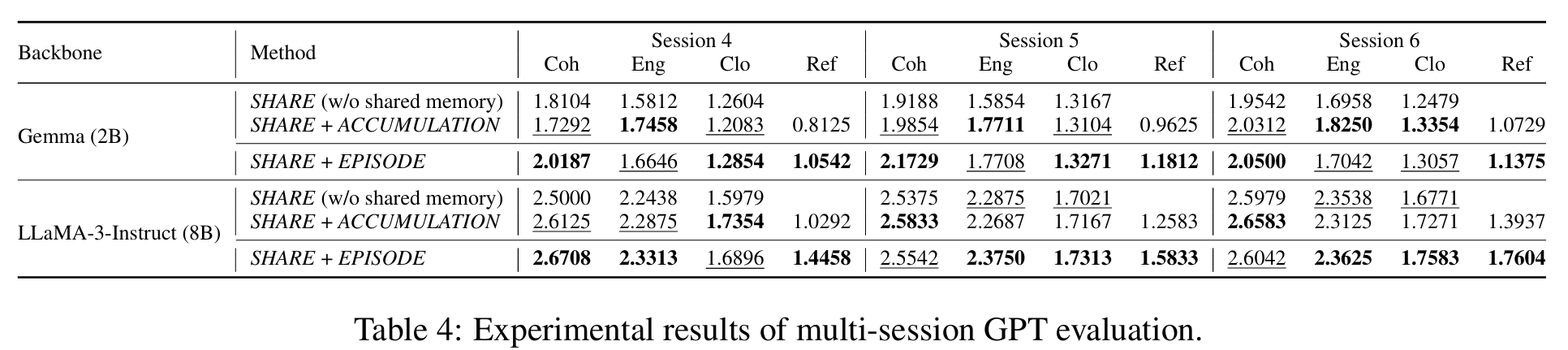
2. 多session测试
测试集:超过6个session的对话。
具体任务:给前两句话、让模型生成八句话。从第三个session开始整合记忆,第四个session开始更新记忆。
对照:SHARE w/o memory(不加入shared memory)、SHARE+EPISODE(记忆更新)、SHARE+ACCUMULATE(只积累不更新)
指标:采取基于GPT的测试方法,四个维度:coherence、engaging(令人保持兴趣)、closeness(对话反映双方对彼此的了解)、reflectiveness(对话体现双方关系)
结果:
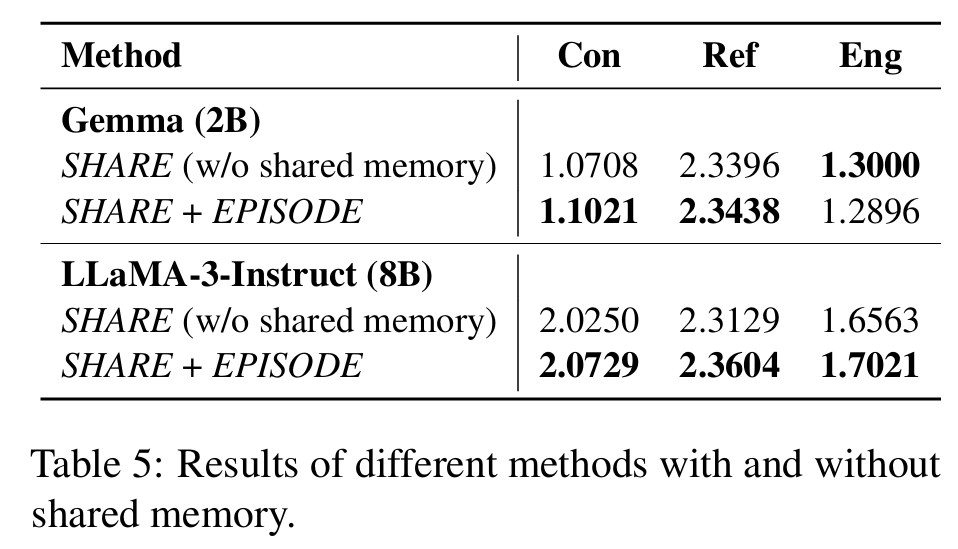
3. 整体测试
不仅仅逐session测试,更要考察跨session之间是否能够连贯、一致。
测试任务:和多session一致
指标:Consistency、reflectiveness、engagingness。其中consistency和之前的Coherence不一样,评估了双方的关系一致性。
结果:
对于Gemma Eng的下降 归因于模型本身能力和表现。
局限性
- 电影脚本生成,对话更加戏剧化,与日常对话可能不够贴近。可能也因此没有做其他benchmark的测试。
- 本质上还是Summary + retrieve,只是提出了“Shared memory”,该有的问题都还存在。
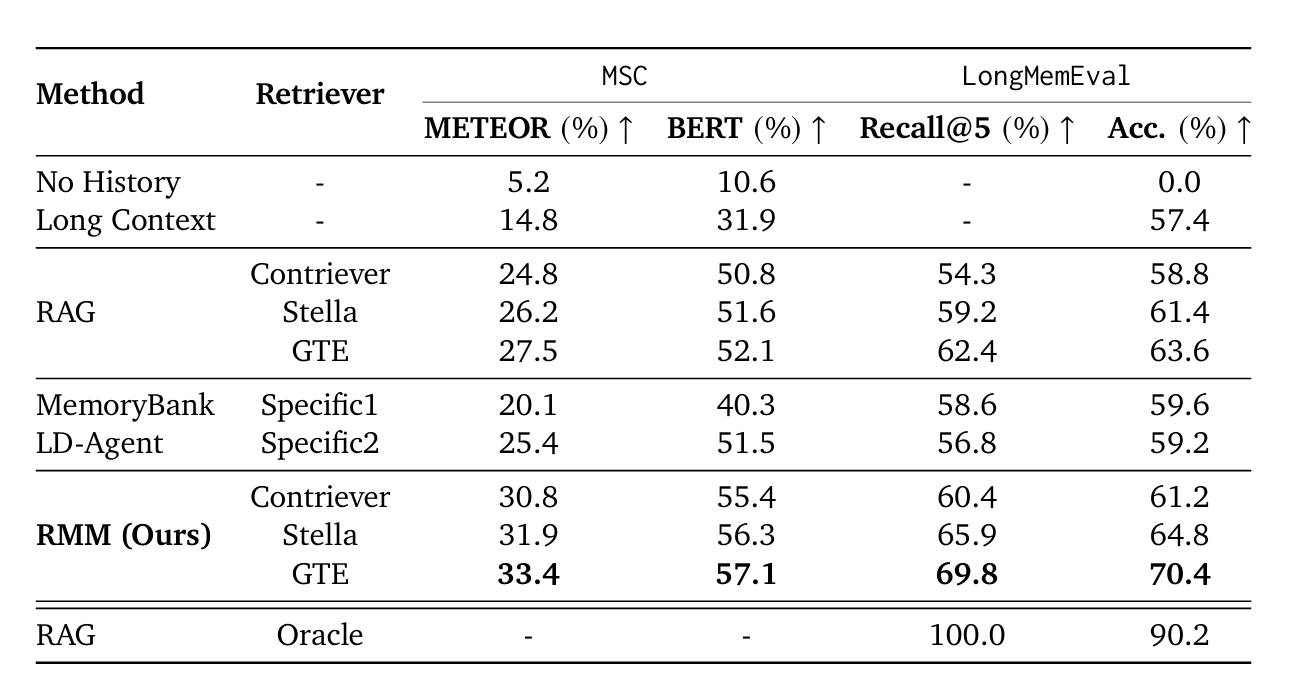
3. In Prospectand Retrospect :Reflective Memory Management for Long-term Personalized Dialogue Agents
实验与结果
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !