数据库理论 期末复习
做题注意
SQL
-
SQL: Projection一定要有DISTINCT!
-
SQL查询:蕴含和NOT EXISTS,ALL,IN
- 至少选修了S2选修的全部课程的人:对于S:不存在一个课程,(这个课程S2选修了,但是:(不存在S选修该课程的记录))
-
SQL:连表查询保险起见还是加上别名
-
子查询的子结果别名:(Select … ) As Name:

-
建表语句:类型写INT,CHAR(100)这类
-
DELETE FROM TABLENAME Where,删除的时候:如果存在外键关系——先删除外键表,再删除主键表!
-
-
INSERT INTO TableName Values()

关系模式与范式
- 判断2NF、3NF时,注意限定对象是“非主属性”,主属性不受约束
ER设计
- 确定1:1, n:1, m:n时注意,1这边是被确定的,如果不能相互确定,就是m:n。画完务必确定:n:1,n这边可以唯一确定1这边吗?
习题
第一次理论作业






一: 3,6,7,9,15,17
第二次理论作业


6 略

二 3, 5, 6, 8,其中第6题的题目要求改为:试用关系代数完成如下查询,并用元组关系演算完成查询(1)(2)(3)。
第三次理论作业


习题三 1,3,4,5, 9。
第四次理论作业
2,6略

习题六:2,6,7 + 补充习题
第五次理论作业
略
习题七: 7,8,10
补充习题

第一章 概述
数据管理技术的发展过程
1. 人工管理
2. 文件系统
3. 数据库系统阶段
应“集成”和“共享”两个要求,数据库系统产生。
核心技术:数据模型和数据独立性
特点:
- 数据结构化:面向全组织
- 冗余度小:不再面对某个应用
- 较高的数据与程序独立性:物理独立性、逻辑独立性
数据模型
1.概念模型
E-R法:实体、练习
2. 数据模型
层次、网络、
概念模型——ER法
ER图的扩充:
- 存在依赖:某实体型的存在依赖于另一个实体的存在,则前者是弱实体
- 标识依赖:如果实体不能由它自己的属性 来唯一标识,而必须通过与它 相联系的另一实体一起来标识 ,那么称该实体标识依赖于另 一个实体。
- 实体子类
数据模型
1. 三要素:数据结构、数据操作、完整性约束
2. 数据结构:数据静态特性描述
3. 数据操作:检索和更新
4. 完整性约束:完整性约束条件
5.分类:层次、网状、关系
1. 层次:树
只能表示二元一对多关系,子节点存取只能通过父节点,不方便
2. 网状:有向图
结构复杂
3. 关系:表格
数据库系统结构:三级模式,两级映像
模式、外模式、内模式;两级映像
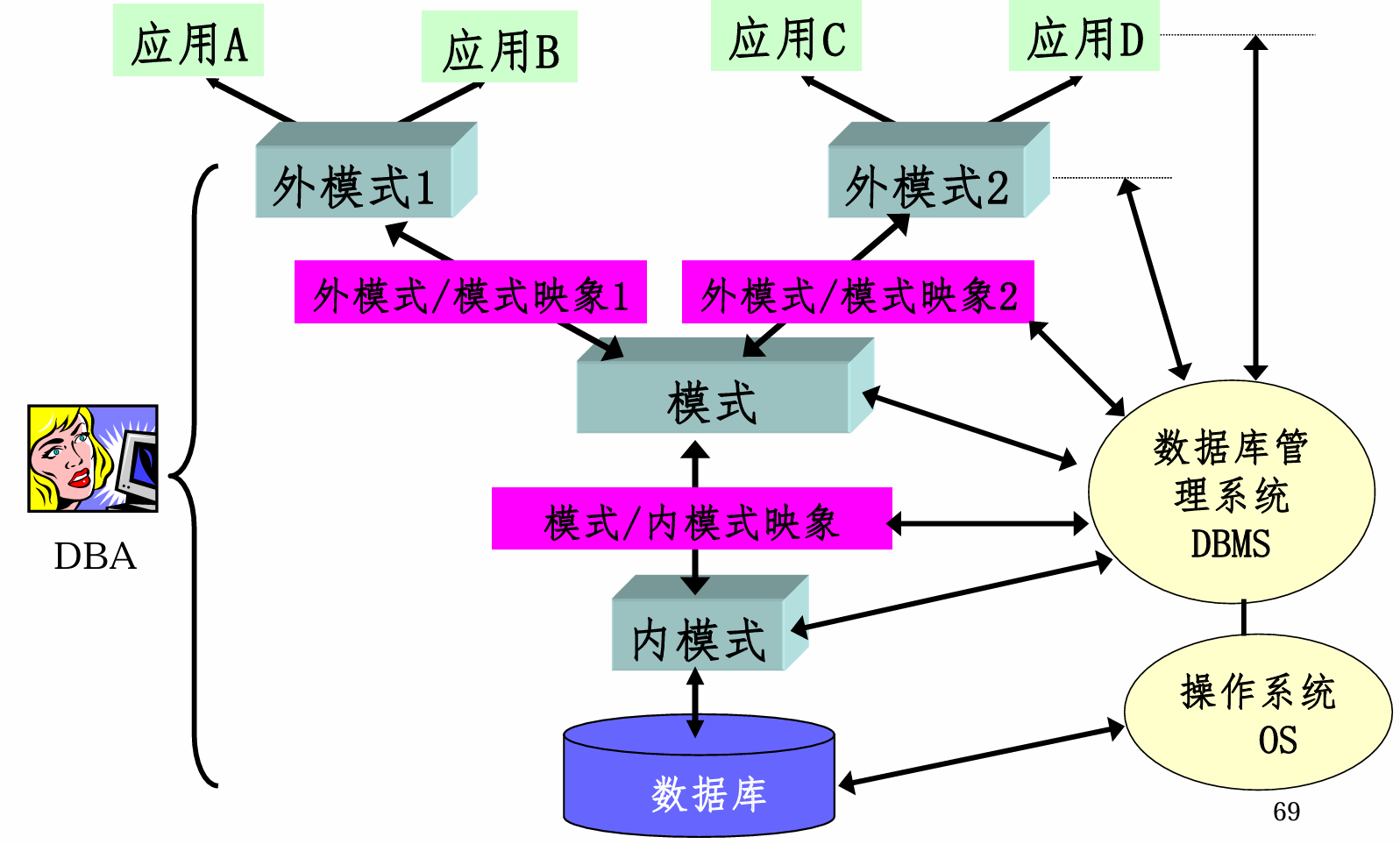
一、模式:三级模式的核心
又称概念模式,在外模式和内模式之间
模式DDL:Data Description Language,模式描述语言,进行模式定义,数据库系统提供。
二、外模式:子模式/用户模式
与某一应用有关的数据的逻辑表示
外模式DDL:定义外模式
三、内模式:存储模式,物理结构和存储方式
内模式DDL
四、两级映像:外模式/模式,模式/内模式
1. 外模式/模式:数据的逻辑独立性
2. 模式/内模式:数据的物理独立性
五、优点
- 数据独立性:物理独立性、逻辑独立性
- 简化用户接口:用户只需要用外模式
- 有利于数据共享:模式产生不同外模式
- 数据安全保密:app只能操作对应外模式
DBMS的功能
1. 提供定义功能
提供三个DDL,用来描述(称为源模式)——>翻译为目标模式,存入数据字典
2. 数据存储
DML语言:data manipulation language
3. 数据库运行管理
并发、存取、完整性约束条件检查和执行、日志、事务
4. 数据组织、存储、管理
5. 数据库建立和维护
DBMS组成
语言编译处理程序、系统运行控制程序、系统建立和维护程序、数据字典(数据库中有关信息的当前描述:三级模式、用户名表、用户权限等)
DBA
管理员(人)
第二章 关系数据库
关系的数学定义
域Di,D1, D2, … Dn上的笛卡尔积$D_1\times D_2 \times D_3 \times … \times D_n$的子集叫D1…Dn上的关系,用R(D1,D2…Dn)表示。
属性:列名
一列:域;
一行:一个元组
度:n,域的个数
码 key
**候选码:**某一个属性组,能够唯一标识一个元组,且具有最小性
**主码:**多个候选码中的一个。
主属性
码中的诸属性称为主属性,不包含在任何候选码中的属性称为非 主属性。
关系性质
列的同质性:每一列的分量来自同一个域,数据类型相同
关系模式
表示方法:R(U, D, dom, F)
语义约束
1. 实体完整性
要有主码,且值不能为空或部分为空。
2. 参照完整性
外部码 外键
F是R的一组/个属性,但不是R的码;但是F和另一个关系S的某个主码Ks对应,F是R的外部码,R:参照关系,S:目标关系
F和Ks必须在一个D上
参照完整性
外键要么为空,要么是S中某元组的主码值。
3. 用户定义完整性*
关系运算——关系代数
传统运算必须在同类关系上做(笛卡尔积一样),包括:并差交和广义笛卡尔积
Selection
$\sigma_F®$, F是条件
Projection
筛选列、去重
$\Pi_{A}®$
Join
笛卡尔积,但是加条件
Natural Join
相同属性、等值连接,另外加上一个Projection去掉重复属性列。
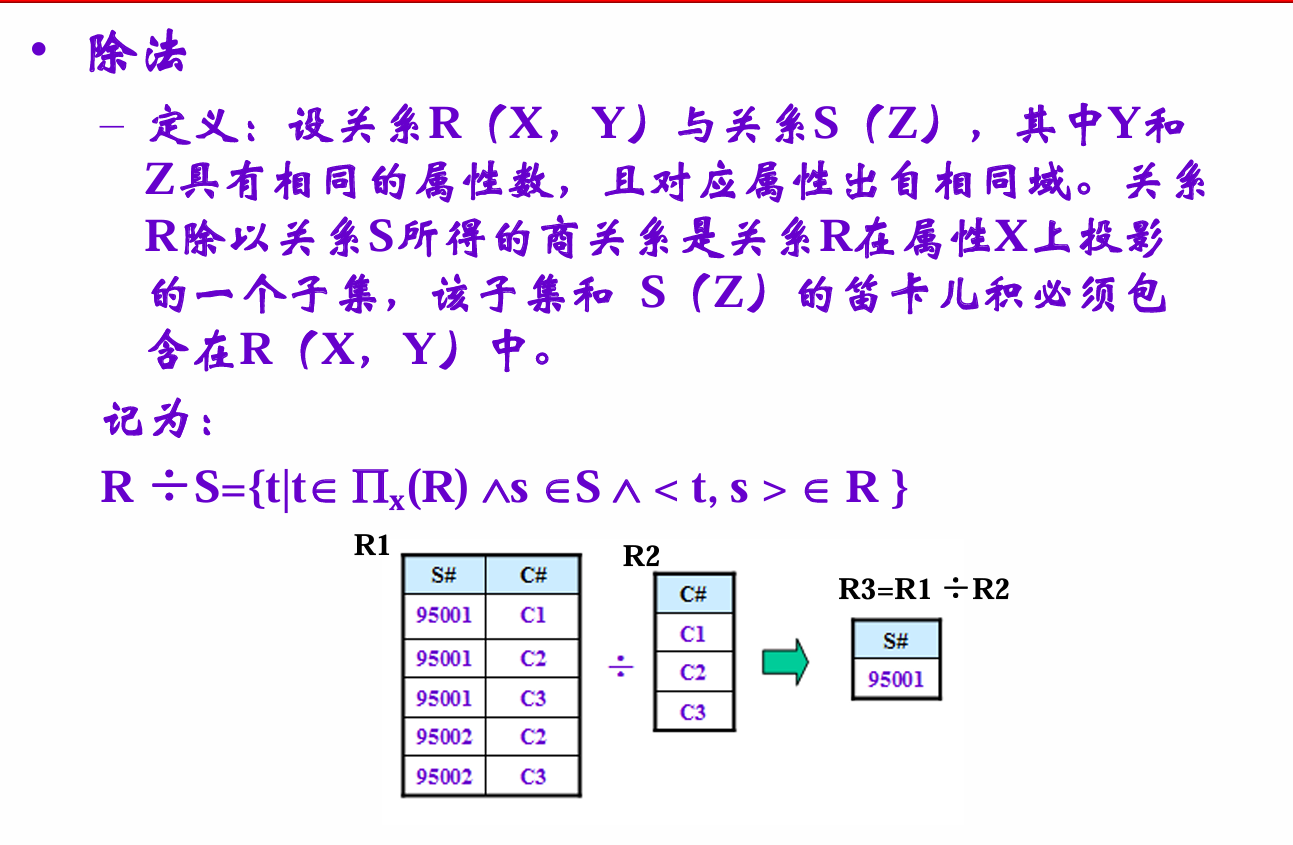
除法
就是打包一下“除数”,发现如果能提出其他部分的公因式(类似整除部分),那么这部分就在商里
元组关系验算
元组演算表达式
类似集合+谓词命题
与关系运算等价:

域关系演算
把元组关系演算中的 变量 换成域变量:
安全约束
安全运算:不产生无限关系和无穷验证的运算
对应表达式:安全表达式
关系代数是安全运算,关系演算则不一定是。
约定一个有限符号集DOM:所有原子值(中间过程、结果)都必须属于DOM
三类运算等价性:
元组演算和域演算表达式,如果加了安全约束后,三者就可以等价了。
数据库语言
数据定义语言DDL:外、内、模式 DDL,三类
数据操纵语言DML:检索、插入、修改、删除(CRUD)
数据控制语言DCL:安全性、完整性、并发控制
关系模型的优缺点

第三章 SQL
特点
面向集合、非过程化
基本概念
基本表、导出表:基本表是真的,导出表是导出来的,包括视图View和快照SnapShot
语法
Select-From-Where
select xxx DISTINCT去重
后接 ORDER
ORDER BY xx, yy DESC/ASC;
连表检索
From后面多个表,可设置别名(实现自身连接)
WHERE后面设置连表条件

外连接
匹配不到也能输出——另一边是空行
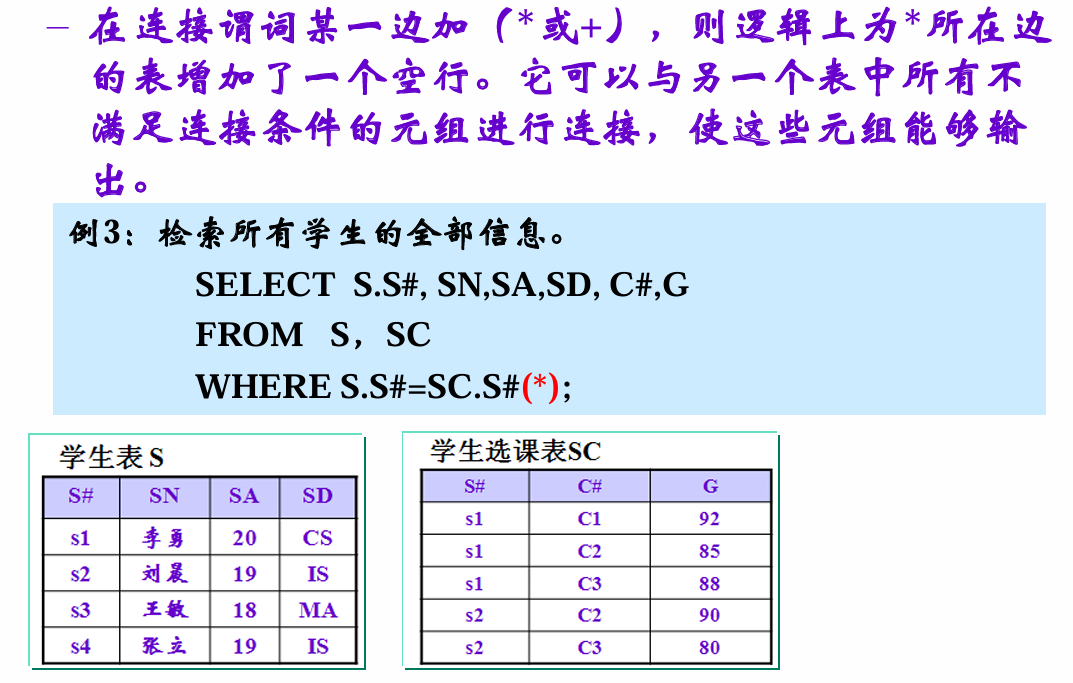
嵌套——子查询
WHERE后面嵌套子查询
两类:普通子查询和相关子查询, 内外查询是否独立
相关子查询的子查询,可能用到外查询的临时值(比如某列的值)
ALL和ANY:用来WHERE中与子查询的一组值比较

In 和 NOT IN

EXISTS 和 NOT EXISTS

NOT EXISTS 双重否定表示肯定:任意

任意都满足<=> 不存在 (一个,使得其不(满足))
把一个Select看成 for + if嵌套呢?

并差交:要求对象相容(同类关系)
UNION、MINUS、INTERSECT:直接放到两个SELECT之间
库函数:只能在SELECT和HAVING(这是什么)
COUNT、SUM、MAX、MIN…
分组检索
GROUP BY xxx HAVING yyy
xxx相同的分一组,满足yyy的组才留下

部分匹配 LIKE / NOT LIKE
WHERE SN LIKE ‘刘%’,以刘开头的名字
%: 任意字符0或多次
_:任意单个字符
派生表——把SELECT结果作为FROM一员
数据定义:基本表、视图、索引
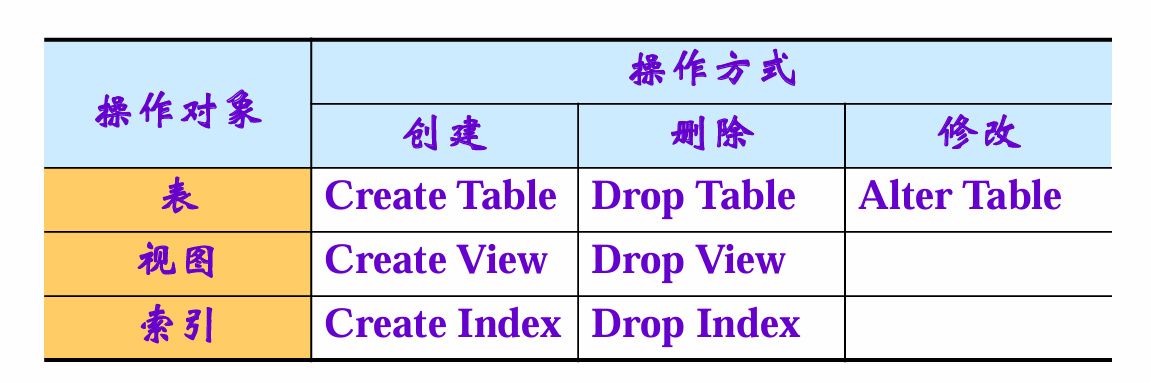
基本表
CREATE TABLE
1 | Create Table NAME |
ALTER TABLE
1 | ALTER TABLE NAME |
Drop Table
Drop Table name;
索引
Create Index
Create [Unique] [Cluster] Index Name
On TableName (ColName ASC, ColName2 DESC);
Drop index
Drop index Name
视图
Create View
1 | Create View ViewName |
Drop View Name
查询视图
对视图的查询实际上并不是真正在视图上做,而是通过 视图消解,即把视图上的操作+视图定义操作 合并,转换为等价的对基本表的查询!
数据更新 SQL:insert、update、delete
INSERT
1 | Insert Into TableName (ColName1, ColName2...) |
Update
Update TableName
Set ColName = ‘value’
Where condition
Delete
Delete From TableName
Where condition
SQL 数据控制
GRANT 权限 [On …] TO 用户
Revoke 权限 [On …] From 用户
Null
算术运算得到NULL,比较得到Unknown——True False Unknown
IS NULL 和 IS NOT NULL
第四章 数据库保护
数据库安全性控制
防止不合法的使用造成数据泄露、更改、破坏——即权限管理。
用户标识和认证
标识:类似唯一用户名
认证:类似密码
存取控制
包括 用户权限定义 和 合法权限检查
分类:DAC和MAC
自主存取控制 DAC
用户对不同数据有不同存取权限,也可以把权限复制给别的用户
基于角色的存取控制
只设置几个常用权限组(比如仅查看、完全权限等),然后给用户匹配对应的权限用户。简化权限管理。
SQL数据安全性控制
- 用户级权限:控制每个用户对整个数据库的权限,和个别数据表无关
- 关系级权限:用户使用关系或视图的权限
GRANT [权限] to XXX
Revoke [权限] from XXX
如果是关系级,就会多一个on tableName
强制存取控制 MAC
按level,用户有一个level,数据有一个level,只有足够匹配才能进
主体:用户;客体:数据库实体,文件、基本表、索引、视图等
主体的许可证等级和客体的敏感度标记比较
读:许可证>=敏感度
写:许可证==敏感度
其他:
1. 视图
2. 审计
3. 数据加密
数据完整性控制
完整性:信息的“正确”,符合语义
数据的 正确性和 相容性
正确性:类型合法、在有效取值范围内
相容性:同一对象在不同关系中数据符合逻辑
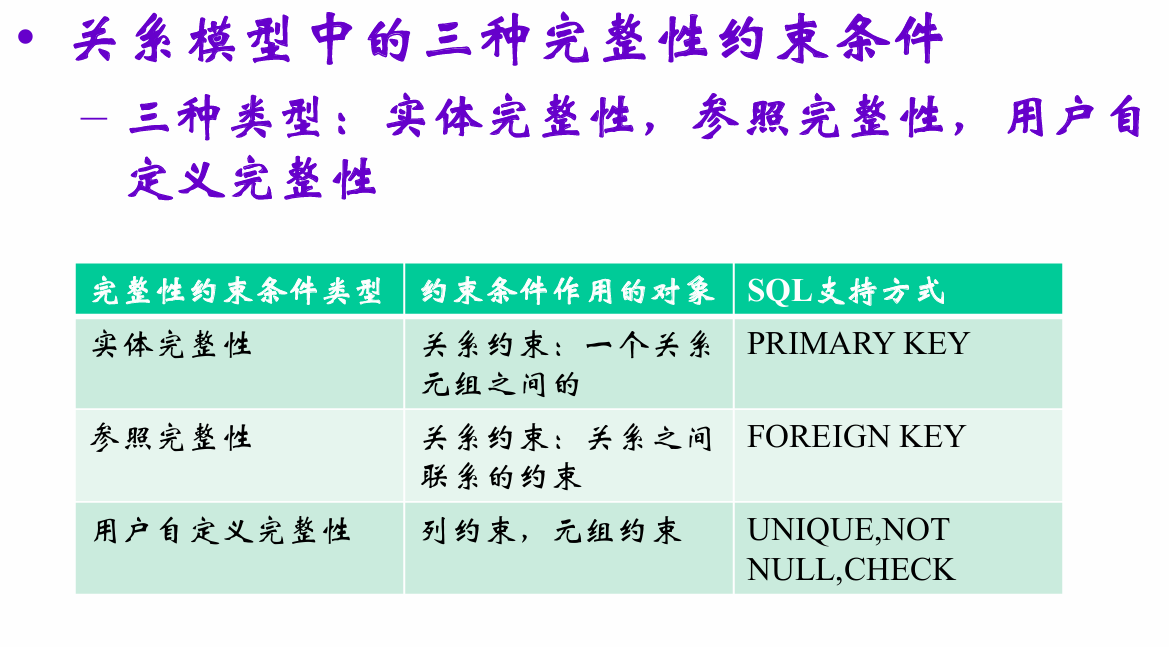
数据完整性约束
对象可以是:列、元组、关系 三个级别
关系模型中的三种完整性约束条件:
静态约束和动态约束
均有三个级别的约束(列、元组、关系)
1. 静态约束
在确定状态数据应满足的条件,反映数据库状态合理性
2. 动态约束
新、旧值之间所满足的约束,反映数据库状态变迁的约束
数据库完整性控制
定义、检查、违约响应
检查时机
立即执行约束和延迟执行约束:一条执行完就检查,和整个用户事务执行完再检查,相同的是检查后不符合都无法插入。
完整性规则五元组表示
DOACP,data,operation,assertion,condition,procedure
In SQL
1. 断言

2. 触发器
事件触发,然后进行操作。
第五章 关系数据理论
数据依赖
函数依赖
X的每个确定值,Y有唯一值与之对应。 则Y函数依赖于X,X函数确定Y。X→Y
平凡依赖和非平凡依赖
平凡: X→Y,若$Y \subset X$,则平凡(我觉得可以理解为没什么用,废话依赖)
无法验证依赖
只能根据语义约束确定一个依赖,但是无法形式化的验证
函数依赖 vs 属性联系
1:m, 1:1, m:n
1的那边是被确定的,即X:Y=1:m,则Y→X
多对多的m:n就没有函数依赖
三种函数依赖:完全、部分、传递
完全函数依赖:少一个都不行
X→Y,但是X少一个(任意真子集X‘)都有X’不能→Y!
部分函数依赖:少一些也无所谓
不满足完全函数依赖,那么就是部分函数依赖
传递依赖
X→Y,Y→Z,且有X不→Y,则Z对X传递函数依赖,X→t →Z
用函数依赖形式化定义关系键
K为R<U, F>中的属性或组合,如果K→f→U,那么K就是R的候选码,多于一个,选一个作为主码
主码:唯一性和最小性
主属性和非主属性:
非主属性:不属于任何一个候选码,对于确定完全没有用
主属性:相反
外键:
属性/组 X不是本关系的码,但是是别的关系的码。

函数依赖公理系统
关系模式R<U,F>中,F中的函数依赖如果能推出X→Y,则F逻辑蕴涵X→Y。
F的闭包就是所有能推出来的函数依赖,记作$F^+$
Armstrong公理系统
三条
- 自反律:$Y\subset X\subset U$,则X→Y一定被F蕴含
- 增广律:X→Y,$Z\subset U$,则XZ→YZ…
- 传递律:X→Y,Y→Z被…,则X→Z…
三条推论

属性集闭包
属性集X关于函数依赖集F的闭包:所有满足X→A能由F根据Armstrong公理导出的A,集合称为$X_F^+$
Armstorng公理系统的完备性和有效性
个人理解为Armstrong公理推F出来的闭包 和 F的闭包是等价的
有效性:用Armstrong从F推出来的,都在F蕴含的里面
完备性:F蕴含的函数依赖的任何一个,都能用Armstrong推出来
证明(略)
函数依赖集的极小化处理(三条规则)
- 拆右侧
- 删左侧
- 删没用的

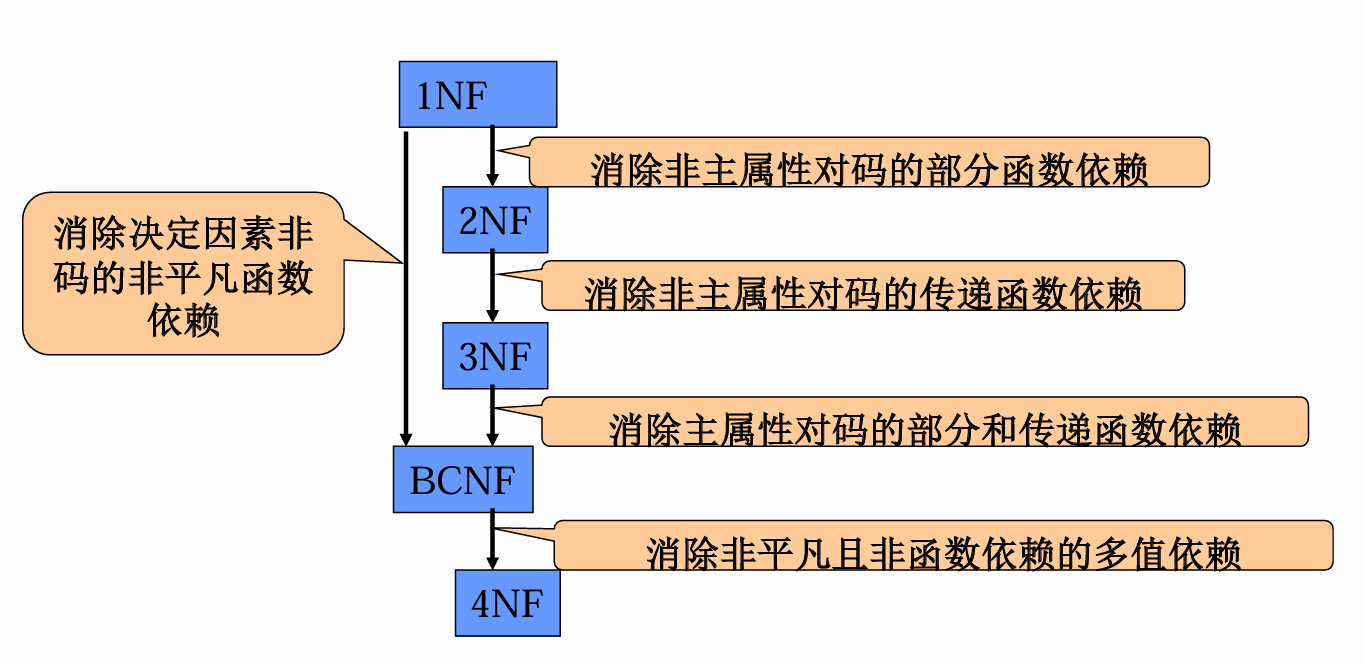
范式
关系满足某个指定约束集,就属于某种范式
1NF
关系只包含原子值,即每个位置数据不可再分。
2NF
1NF基础上,每个非主属性完全依赖于码,即1NF消除了部分依赖
比如
$UN (S# ,CN,G,SDN,MN)\in 1NF$,表示学号、课程名称、成绩、学生学院、院长姓名。那么S#和CN是码,SDN被S#就可以确定,于是部分依赖于码,不是2NF。
拆成:

但是传递依赖导致还是存在插入异常、删除异常和数据冗余
3NF
2NF中,每个非主属性都不传递依赖于R中的任何码,那么就是3NF。
规范为3NF:投影分解
将2NF中的传递依赖拆开,分开以后各自就都是3NF。
BCNF
3NF中主属性的传递和部分依赖仍然存在。
于是BCNF:任何非平凡依赖X→Y,X必然含有码。
多值依赖
这里有点弯弯绕
$R(U)$表示在属性集U上的关系,其中X、Y、Z是U的子集且满足$Z=U-X-Y$。$R(U)$中的多值依赖X→→Y成立,当且仅当对任意关系r,给定(x,z)的值,有一组Y的值,且这组值仅仅决定于x,和z无关。

结合下面的对称性,感觉我会理解为:多个值都依赖于X,且这些值之间相互独立(整了个笛卡尔积出来?)
性质
对称性:X→→Y,则X→→Z,其中Z=U-X-Y
**函数依赖:**X→Y,那么X→→Y。
**平凡:**X→→Y,而$Z=\emptyset$,那么就是平凡的
4NF
1NF的R (U, F),如果每个非平凡多值依赖X→→Y (Y$\not\subset$X),X中都含有码。那么就是4NF。
或者在BCNF基础上定义:BCNF的R,不存在非平凡非函数依赖的多值依赖,那么就是4NF。
减少数据冗余
范式规范化总结
1NF:不可再分
2NF:非主属性完全依赖于码
3NF:非主属性不传递依赖于码
BCNF:任何非平凡依赖的决定因素(左边)都包含码
4NF:任何非平凡多值依赖的决定因素都包含码 / BCNF中不存在非平凡、非函数依赖的多值依赖
模式分解理论
关系模式分解
通俗理解,是把关系R中的属性集U进行一个分(可以有交集,但是不能有包含关系),然后把对应的关系分到各自的新R中。

分解的无损连接性
就是分了以后再join回来,不会少数据。
判断算法
建立$k\times n$的表,n个属性n列,k个分解k行,i行j列表示第j个属性是否包含在分解i中,如果包含,赋$a_j$,否则$b_{ij}$
每次根据函数依赖X→Y,如果有两行能使t1[x]=t2[x],那么就更新对应Y的所有属性,如果某一行Y中有a,其他行改为a,否则就让靠上的行改为下面行的b。
如果做到某一行全是$a_j$,说明无损。
判断定理
充分必要条件:$U_1 \cap U_2\rightarrow U_1-U_2 \in F^+$ 或把右边换成U2-U1
即:U1和U2的交集能够决定U1 or 能确定U2
分解的 保持函数依赖性
把函数依赖集合$F_i$取并集,再闭包和原来的$F^+$一样
就看F中的每个X→Y,Y是否属于$X_G^+$。
投影分解应该遵循 无损连接 和 依赖保持
分解能达到的范式
保持函数依赖更难
要求保持函数依赖——总能到3NF,但是不一定BCNF
要求无损连接——4NF
都要求——能到3NF,但不一定BCNF
模式分解算法
达到3NF的等价模式分解
1. 保持函数依赖
- F极小化
- 扔掉F中不出现的属性
- 不可再分条件:存在X→A,且XA=U
- 按F中的相同左部分组,每组涉及所有属性为Ui,如果存在$U_i \subset U_j$,删掉Ui保留Uj。最后得到分组
2. 函数依赖+无损
先保持函数依赖,然后保证有一个完整的码在某一个Ui中。
- 先得到一个保持函数依赖的3NF分解ρ
- X是R的码,如果已经有$X\subset U_i$,那么不用动,ρ就满足无损连接;否则手动加一个只有码的,令$\tau =\rho \cup {R*<X,F_X>}$
达到BCNF无损连接
感觉上就是,既然X→Y中X不包含码,即X无法确定一个元组,那就不断分使得X足以确定整个元组(把确定不了的都单独分出去)
步骤:
对于一个分解,如果有一个R_i不是BCNF,那么对于这个Ri进行再次分解
对于不是BCNF的Ri,一定存在$X→A$,且X不包含码,那么Ui中一定包含X和A以外的元素(XA是Ui真子集),否则X就可以唯一确定元组了。这时候把XA分一组,U-A分一组。
求解候选码
将R<U,F>中的属性分为四类:
- L类:只出现在F左侧
- R类:只出现在F中右侧
- N类:左右都不出现
- LR类:左右都出现
定理
- 如果X是L类,X必然为R中任意一个(in all)候选码的成员
- X是R类,那X不在任意(in none of)候选码中
- N类,必然包含在(in all)任意一个候选码中
- 唯一候选码:X是N和L的集合,如果$X_{F}^+=U$,那么X为唯一候选码
依赖图
点表示属性,有向边表示依赖。
本质还是看L类和N类
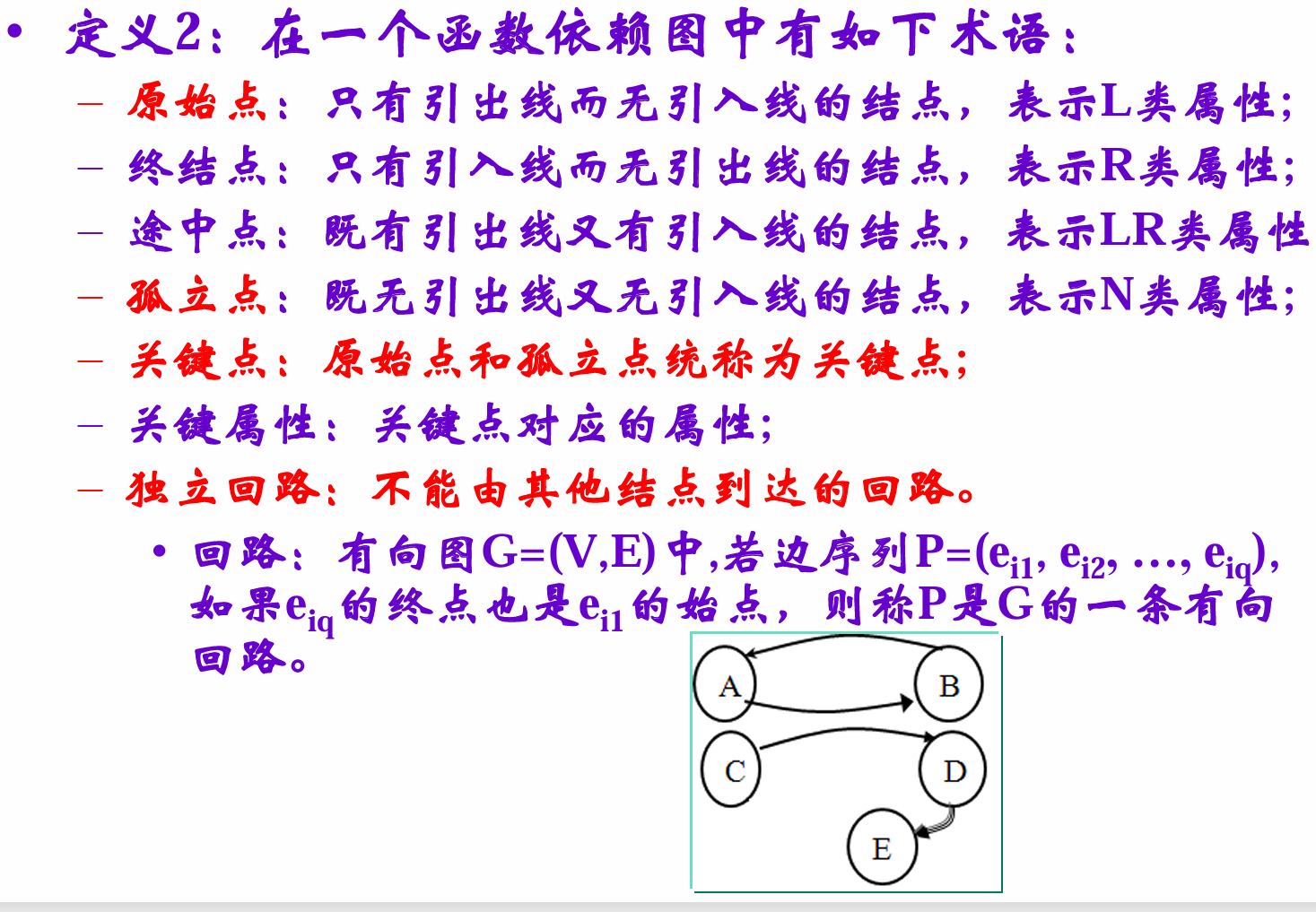


有用的定理:
LR类在候选码
充要条件:它是某个独立回路中的结点
候选码排列组合论
如果有独立回路,那么显然候选码不唯一,每个候选码=关键属性+k个回路中的一种选择
所以数量 = $\Pi_1^k |round_i|$ (后面那部分的组合方法)
图论算法
- 最小化F得到Fm
- 构造G,找到关键属性集X (L&N)
- 找独立回路,根据X+回路 构造所有情况
多属性依赖集候选码求解
个人认为本质相同,还不如上面的直观。

第六章 数据库设计
对于一个给定的应用环境,设计优化的数据库逻辑结构和物 理结构,建立数据库,使之能够有效地存储数据,为开发满足用 户需求的应用系统奠定基础。
设计方法
手工设计
琐碎复杂、难以评价、移植
规范设计
划分阶段,逐步迭代
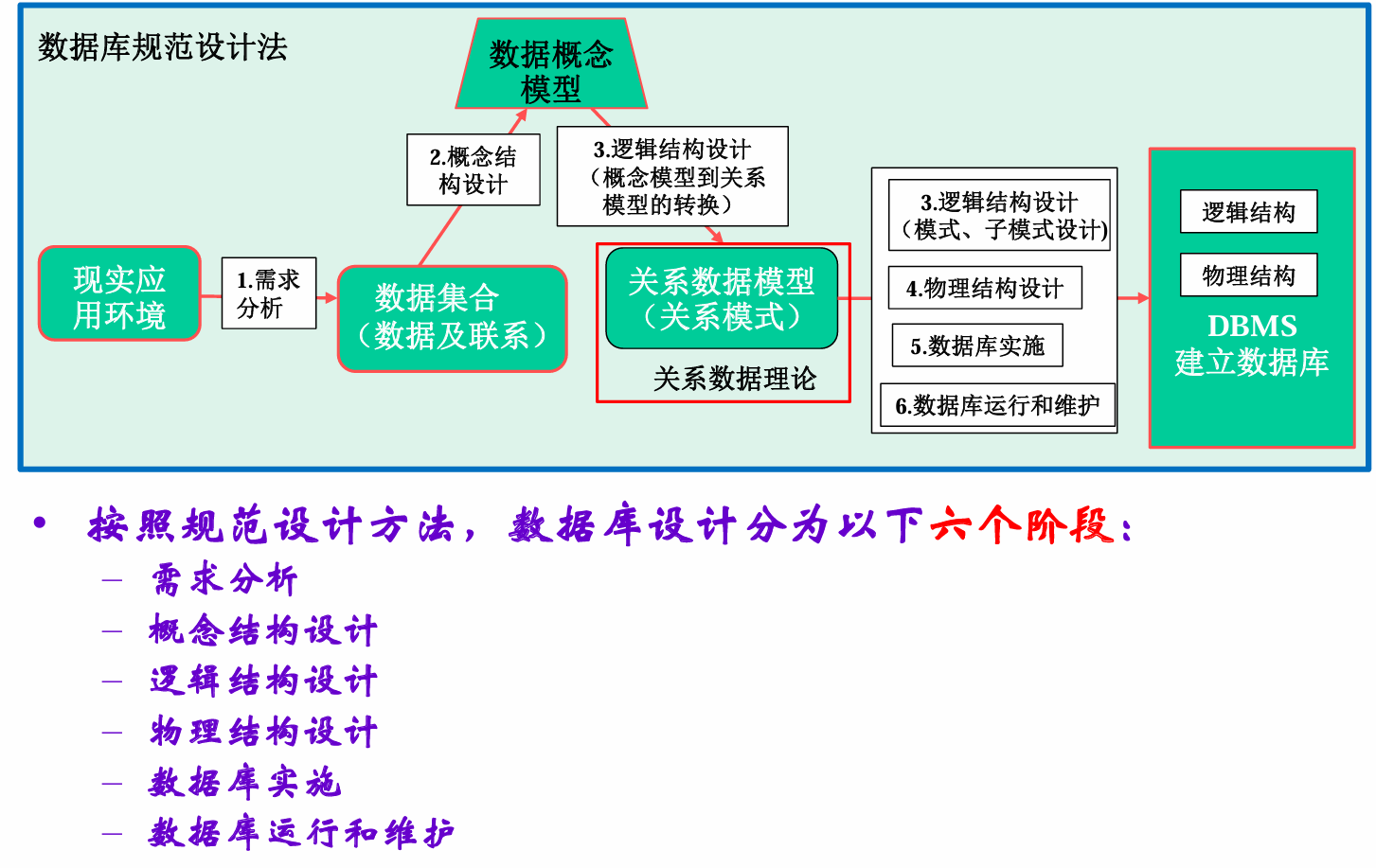
设计阶段概述
-
需求分析
-
概念结构设计:ER图
-
逻辑结构设计:把概念模型 转为 DBMS支持的 数据模型
-
物理结构设计:在物理设备的存储结构、存取方法;1. 确定内模式 2. 对物理结构进行时空效率评价
-
数据库实施:建立数据库,三类DDL
-
运行与维护
需求分析
-
处理要求:处理功能
-
信息要求:数据之间联系
-
安全性与完整性要求
数据流图
表达数据和处理之间的联系
自顶向下,逐步分解
数据字典
描述系统各类数据,类似数据元素表
- 找出所有原子数据
- 有联系的组成数据组
包含:
- 语义定义
- 类型定义
- 完整性约束定义
概念结构设计 —— ER法
ER组成:实体、联系、属性
实体:长方形
联系:菱形
属性:椭圆形
四类设计方法
自顶向下
全局框架,逐步细化
自底向上(最常用)
局部结构,然后集成
逐步扩张
核心概念开始,向外扩充
混合策略
自顶向下全局+自底向上局部
自底向上设计方法
两阶段:局部ER图、合并局部ER形成总ER
局部E-R设计
- 选择局部应用
- 建立实体模型
- 确定实体间联系
- 画ER图
1. 实体模型建立
根据数据字典进行初步抽象,得到实体、属性,再按原则调整。
原则1:属性不可再分
原则2:属性不能和实体有联系==调整为==>实体和实体联系
原则3:实体vs属性应该是1:1或n:1,否则就应把属性上升为实体
分ER 到 总ER
两种集成方法
- 多个ER一次集成
- 累加法,每次吸纳一个
集成和集成后
- 合并:解决冲突
- 修改重构:消除冗余生成基本ER图
合并——消除冲突
包括属性冲突、命名冲突和结构冲突
- 属性冲突:类型、取值范围不同——协商解决
- 命名冲突:同名异义,异名同义——建立命名表,统一命名
- 结构冲突:同一对象可能在这边是属性,在另一边是实体——变一致+取并集
修改初步ER图——基本ER图
两种方法消除冗余
- 分析法
- 规范化方法
分析法
看起来是瞪眼法
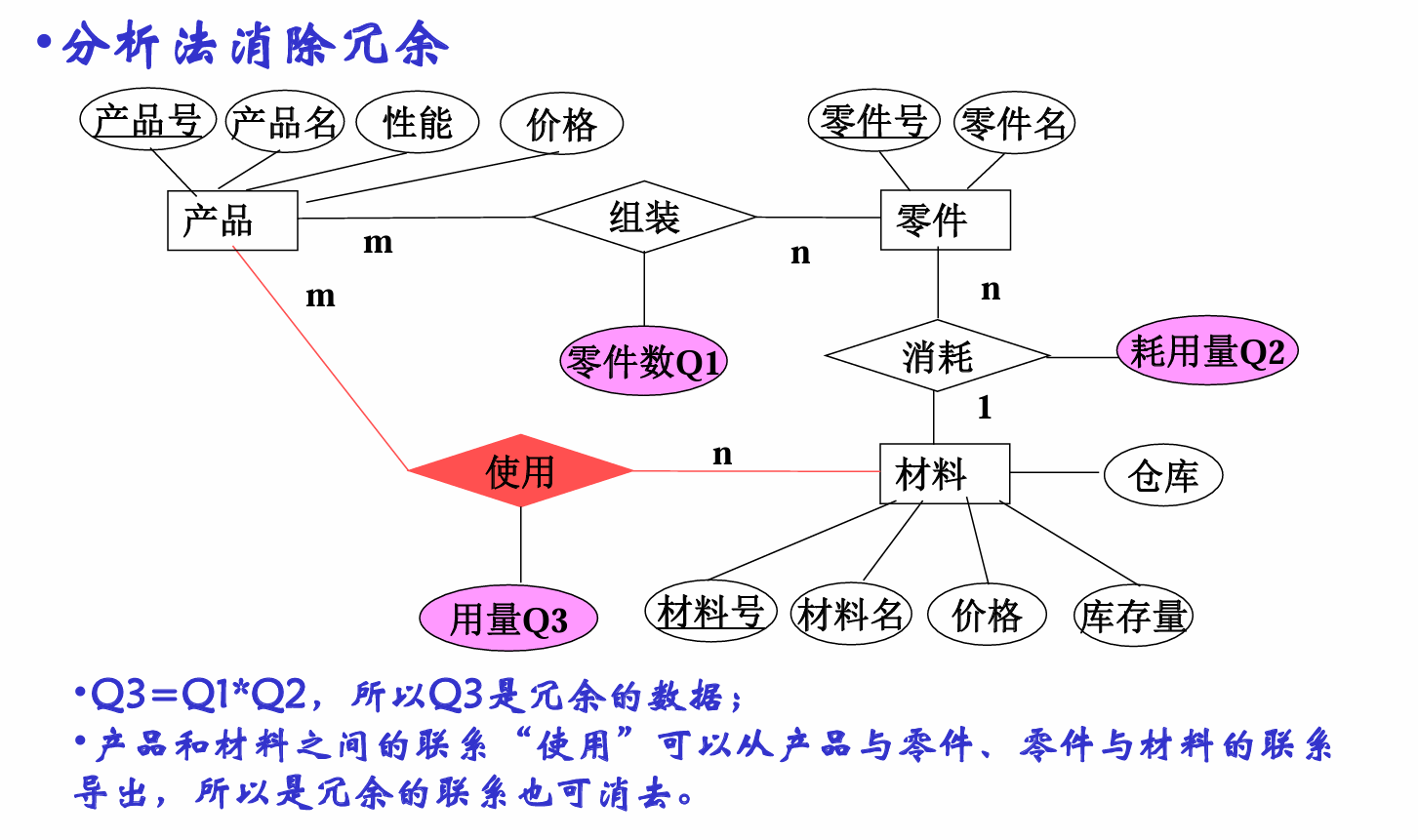
规范化方法
利用最小覆盖算法

逻辑结构设计
具体包括:
- 形成初始关系数据库模式
- 关系模式规范化
- 关系模式优化
- 子模式定义
ER到关系模型的规则
实体型、联系(包括多元联系)都转化为一个关系(即数据库中一个表)
对应关系中,属性就是对应被转化主体(实体型、联系)的属性(如果是联系还需要加上实体的码)
对于弱实体类型(必须依赖其他实体的存在),在其关系中加入被依赖实体的主码作为外键。
有相同码的关系可以合并。
个人总结
这里我觉得就是,只需要对于:实体、m:n关系建立关系模型,因为1:1和1:n的都会合并(1:1的注意看看能不能两个实体合并)
规范化与优化
规范化:确定范式等级
优化:确定是否进行模式合并和分解
1.水平分解
对数据分组,另设关系
2.垂直分解
对属性分解,形成关系子模式。必须保证两个特性:无损连接和保持函数依赖
用户子模式 (视图)
…
物理设计
确定存储结构、选择存取方法
存取结构
- 确定存放位置
- 确定系统配置
存取方法
- 索引
- 聚集
- 哈希
1. 索引
为加速数据访问设计。
索引记录/索引项的组成:索引域(关键字?)+指针(指向存储位置)
**常用:**B+树
索引域选取:经常作为查询条件、作为连接属性、作为max/min等库函数参数
2. 聚集
把关系中,某个属性/属性组值相同的记录放到连续物理空间。
能提高查询速度
一个关系只能参加一个聚集
原则:
- 经常join的关系可以聚集
- 单个关系某组属性经常 ‘=’ 比较
- 关系某个属性组值重复高
但是 维护消耗也大,更新>>连接 时 就不应该用了。
3. Hash
将关键字转为地址
在关系大小可预知、不变 or 关系大小动态变化但是DBMS提供动态hash存取方法=>可以考虑hash
第七章 存储管理和索引
数据在磁盘中存储,但是在主存中才能被使用。DBMS就是要尽量减少IO传输(磁盘存取速度),使得主存中尽量多的块使得上层访问某块时,他在磁盘中概率最大。
磁盘
以块为单位传输
访问时间
寻道时间+ 旋转时间+传输时间
物理存储管理器
DBMS结构最底层,负责操作数据在磁盘和主存之间的移动等。
可以 使用操作系统的文件系统 or 自己实现,支持跨平台和一些操作系统不提供的功能
数据库存储结构/物理结构
数据库——文件——块/页
逐层包含,页是存储分配和数据传输的单位
DBMS的存储管理器负责维护数据库文件,将其组织为块/页的集合,跟踪页的读取写入和可用空间。
文件中组织结构===>文件中 记录的组织方式
表——>文件——>多个记录—映射到—>磁盘块
其中分配方法有四种:
连续分配、链接分配(包含指向下一个数据块的指针)、按簇分配(一簇多块,簇间指针)、索引分配(索引块指像数据块)
页
有唯一标识符ID,DBMS映射到物理位置
页 = 头部header(页大小、checksum、DBMS信息等) + 数据
页的Slot结构
Header记录了已经使用的槽数、最后被用槽的起始位置偏移量和一个槽数组(每个元组的起始位置偏移量)。
增加记录时,槽数组从开始到尾部的方向增长,而记录数据则从数据区的尾部到开始的方向增长。当槽数组与元组数据连接到一起 时,认为页满。
记录
DBMS将其解释为属性类型和值。
组成:
头部元数据(元组元数据)+记录数据(实际数据)
唯一标识符ID
文件的记录组织
堆、顺序、索引、散列、聚集等方式
1. 堆:放哪都行
链表方式 和 页目录方式
2. 顺序
按搜索码排序排列
搜索码:用于在文件中查找记录的任意属性或属性集合
还是链表
3. 索引
主文件(数据)+索引表
索引表按关键字有序
4. 散列
哈希函数设计+冲突处理(二次检索)
5. 聚集
具有相同或相似属性值的记录存储于连续的磁盘块中
多表聚集:将多个关系存储于一个文件中,在每个块中存储两个或更多关系的相关记录。可以加快特定的连接查询,但会使单个 表的访问变慢
缓冲区管理系统
缓冲区管理器:负责缓存空间分配,内外存交换
读取时在缓冲区内-正常返回,否则替换(写回)
元数据:页表
共享锁与排它锁
替换策略:LRU等
索引
索引记录:索引文件的记录, 包括 : 索引域(搜索码)+指针
分类方式
排序索引 与 哈希索引
排序的 or 使用索引域上hash函数确定位置
聚集索引 与 非聚集索引
聚集索引(主索引):搜索码值的排列与记录在文件中的排列顺序一致
非聚集索引(辅助索引):顺序不同。
稠密索引 与 稀疏索引
稠密:每个搜索码值都有索引,可以直接搜,时间快但是空间大
稀疏:只有部分索引域值有索引记录,文件以索引域排序时有用。(搜索k时候要找到比k小的最大索引,然后顺序遍历)
稀疏空间小、查询慢,非聚集索引都是稀疏的。
多级索引
多一层稀疏索引,减少空间占用
二叉树索引
每个节点一个关键字,左儿子小于,右儿子大于
多枝树索引
D个关键字,那么就有D+1个指针
B树
限制了每个节点放置关键 字与指针的最小和最大个数。
从树根到叶节点每条路径的长度都相同,因此所有的 叶节点都在同一层上。
关键字散落在各层上,每层都有指针
B+树
关键字都在叶节点上,从左到右递增排列。可以同时顺序或随机查找,数量限制和B树一样。
但是中间结点指针都是指向下一层,只有叶子结点才是指向记录。
查询
比较、遍历,直到到达指定叶子结点;没找到说明没有该值的记录。
插入
按照查询方法找到该插入的位置,这时候:
- 如果有位置(叶子结点数量小于n-1),就正常插入
- 没有位置,需要拆分——当前节点的前一半不变,后一半放到右侧新创建节点,然后在父结点插入,向上递归插入直到不需要拆分。
删除
删除如果码的个数低于下限,可能需要合并/重新分配
- 合并:和兄弟合并,把自己从父节点删除
- 合并后发现超过上限:与兄弟之间重新分配指针。
B+树文件组织
在B+树文件组织中,叶节点存储了记录而不是指针。
Hash索引
哈希表:哈希函数 + 哈希冲突方案
静态hash:表大小固定
文件增大,过多溢出性能降低;缩小则空间浪费
动态哈希:哈希表大小动态修改
定期重哈希 或 线性哈希(递增重新哈希)
特点
周期性重组开销大、适用于特定值检索(精确检索)而非区间值、部分匹配
第八章 查询处理与查询优化
概述
关系查询步骤
查询分析、查询检查、查询优化、查询执行
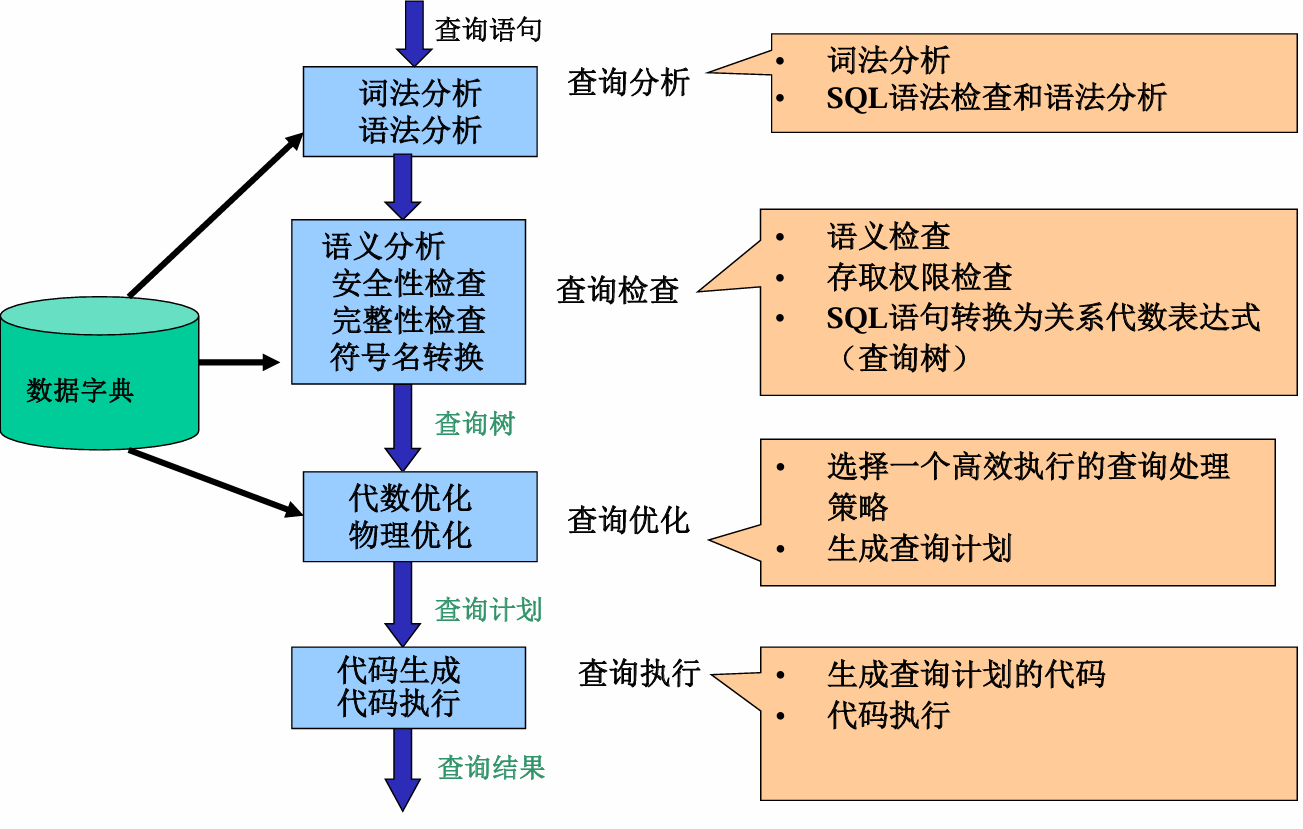
查询代价度量
- 磁盘类:IO代价最重要
- 网络数据库:网络延迟
磁盘访问代价:
用 访问磁盘的块数 进行估计
查询操作实现
Selection
全表扫描法 和 索引扫描法(如果条件对应的属性有索引)
排序
- 内存中放得下:quicksort
- 内存里放不下:外排序-归并算法
连接 join
嵌套-循环法
第一个表外循环、第二个表内循环。
应该让小表在外
块数 = br + br /(k-1) * bs
索引连接
第二个表按照连接属性建索引,用第一个表元组的连接属性和第二个表连接属性比较
有索引的在内层,对于外层的每一个元组,可以根据索引快速找到;如果都有索引,小的在外
排序-合并法(只能等值连接 或 natural join)
都按照连接属性排序,然后对连接属性比较
类似归并排序的双指针移动法。
块数 = br+bs
Hash-join(等值 或 natural)
用同一个函数把两个连接表的元组散列到同一个hash文件。
用hash分别将s和r分成k组。只需要比较s[i]和r[i](哈希后在同号组是相等的必要条件)。
其他操作
去重:重复数据相邻,只留一个
排序、哈希
Projection:每个元组Projection + 去重
集合运算:并 差 交
可参考 : 排序-合并连接 ; hash join 两种思路
库函数
分组属性排序/散列聚集同组元素,然后执行
表达式的执行
物化方法 materialized
需要有临时表存储中间结果,额外存取操作的浪费
流水线 pipeline
不需要存储中间结果,同时执行多个运算,将结果传递给下一个运算
但对有些运算不适用(排序)
查询优化
目标:最小代价
总代价 = IO代价 + CPU代价 + 内存代价
主要考虑IO
分为代数优化和物理优化,优化后得到一个执行操作的顺序。
代数优化
关系代数表达式的优化,即按照一定的规则,改变代数表达式中操作的次序和组合
规则
- join和$\times$的交换/结合律
- Projection嵌套的简化(看最外层 和 内层的交)
- Selection和Projection交换律
- Selection 下放到 $\times $之前:

- 先选择后并、先选择后差、先选择后nj
- 分别投影然后再$\times $
- 先投影在并
总体原则
- 先选择、投影
- 尽量Selection和Projection一起做,减少遍历次数
- $\times$和Selection可以合并为join
- 中间结果复用
查询树优化
-
按照整体原则优化:尽量下放Projection和Selection
-
叶子结点加Projection去掉无用属性
-
$\times$+ Selection = join
-
分组:双目运算+单目运算的一系列祖先(比如pro和sel等)分为一组
-
按组先进行操作(意味着这一系列操作肯定是pipeline)
物理优化
存取路径和底层操作算法的选择。
基于启发式规则的操作算法选择
Selection
小的全表扫描,大的可以考虑索引
Join
两表都已按条件属性排序——排序合并
一个表有索引——索引连接
未排序、无索引,一个较小——hash join
或者 嵌套循环
代价估算(基数估计)
用统计信息计算出方案大小,然后选一个估计最小的。
查询优化的一般步骤
查询——语法树——查询树优化——启发式物理优化,生成查询计划
第九章 事务处理
事务 transaction
用户定义的数据库操作序列,不可分割。是数据库恢复和并发控制的基本单位。
性质:ACID
- 原子性:要么都做,要么都不做,不可分割 由恢复机制实现
- 一致性:执行前后数据库都应该处于一致性状态 由事务原子性保证
- 隔离性:并发执行也不能干扰事务执行,即事务的处理是隔离的 由并发控制实现
- 持久性:事务执行结果是永久性的 由恢复机制实现
但是要防止:1. 并发打断 2. 强制终止=====>数据库并发控制机制、恢复机制。
定义
用户显式控制事务的开始和结束。
SQL中:
1 | BEGIN TRANSACTION # 事务开始 |
数据库恢复
把数据库从错误状态恢复到某一已知正确状态,通过 数据库管理系统的恢复子系统,保证了 事务原子性 以及 故障后能正确恢复
故障种类
1. 事务内部故障
可预期
不满足条件导致回滚
不可预期
处理不了的,死锁、溢出、违反完整性规则…
2. 系统故障
使系统停止运行,事务异常中断。但是不破坏数据库。
3. 介质故障
外存故障,如磁盘损坏等。
会破坏数据库,影响存取这部分数据库的所有事务。
4. 病毒
非法修改数据
恢复
评估影响
数据库本身被破坏——介质故障
数据库没被破坏,但数据可能不正确——事务、系统故障,病毒
恢复原理
冗余,利用其他地方的冗余数据恢复/修正。
实现技术
实现两个目标:1. 建立冗余 2.利用冗余进行恢复
数据转储
DBA定期复制数据库内容到其他地方(磁带、磁盘),备份。
分为 静态转储 和 动态转储
- 静态:没有事务运行时,转储,不允许中途存取/修改;一致性,但是降低可用性
- 动态:可以边执行事务边转储;不影响可用性,但是不保证正确,还要建立日志记录转储时的事务对数据库的修改
两种转储方式: 海量转储 和 增量转储
- 海量转储:全量转储
- 增量转储:$+\Delta data$
日志建立
记录事务对数据库更新操作
- 以记录为单位
- 以数据块为单位
事务故障和系统故障恢复必须使用日志文件。
静态转储:用日志来恢复转储结束——故障之间的事务
动态:后备副本+日志 才能恢复
先记日志 再写数据库
恢复策略
事务故障——UNDO
按日志回滚,做逆操作,直到开始。
系统故障——UNDO+REDO
未完成的可能已经提交到数据库;已完成的可能还在缓冲区未写入
所以UNDO未完成+REDO已完成
介质——副本恢复+日志redo
检查点技术 in 日志
记录:检查点时刻所有正在执行的事务清单、这些事务最近一个日志记录的地址
重新开始文件:记录检查点记录在日志中的地址
检查点维护:1. 写入日志 2. 日志中写入检查点 3.写入数据 4. 把检查点地址写入“重新开始文件”
恢复:1. 重新开始文件定位最近检查点记录 2.检查点记录中得到当前正在运行所有事务 3. 故障时已经提交的事务REDO,否则UNDO(保持事物原子性、防止不一致)

数据库镜像
自动把整个DB或其中的关键数据复制到另一个磁盘上,由DBMS自动保证镜像数据库与主数据库的一致性。
并发控制
并发:提高吞吐量、减少平均响应时间;但是 同时存取同一数据可能造成不一致
三种并发导致的不一致
Lost Update
两个事务都进行更新,但是后更新的把前一个更新的覆盖使其修改丢失(我认为本质是其读的结果没有正确接续)

Dirty Read
T1修改,T2读,T1 Rollback,这时候T2读的还是脏数据,不一致
Non-Repeatable Read
T1在T2修改前后两次读取,结果不同
封锁
排它锁(X锁) 和 共享锁(S锁)
排他锁X:唯一RW
T对R上X锁,那么只有T能读写R,其他事务的任何封锁请求都失败
共享锁S:全部readonly
T对R上S锁,T只能读;其他事务也只能上S锁
三级封锁协议
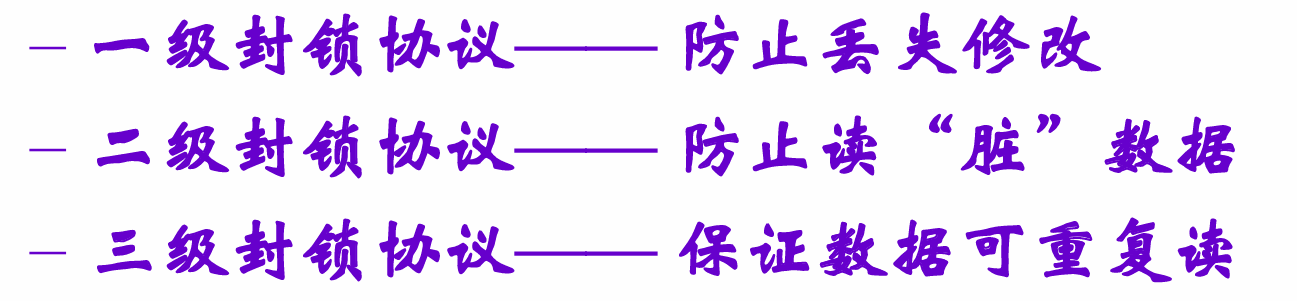
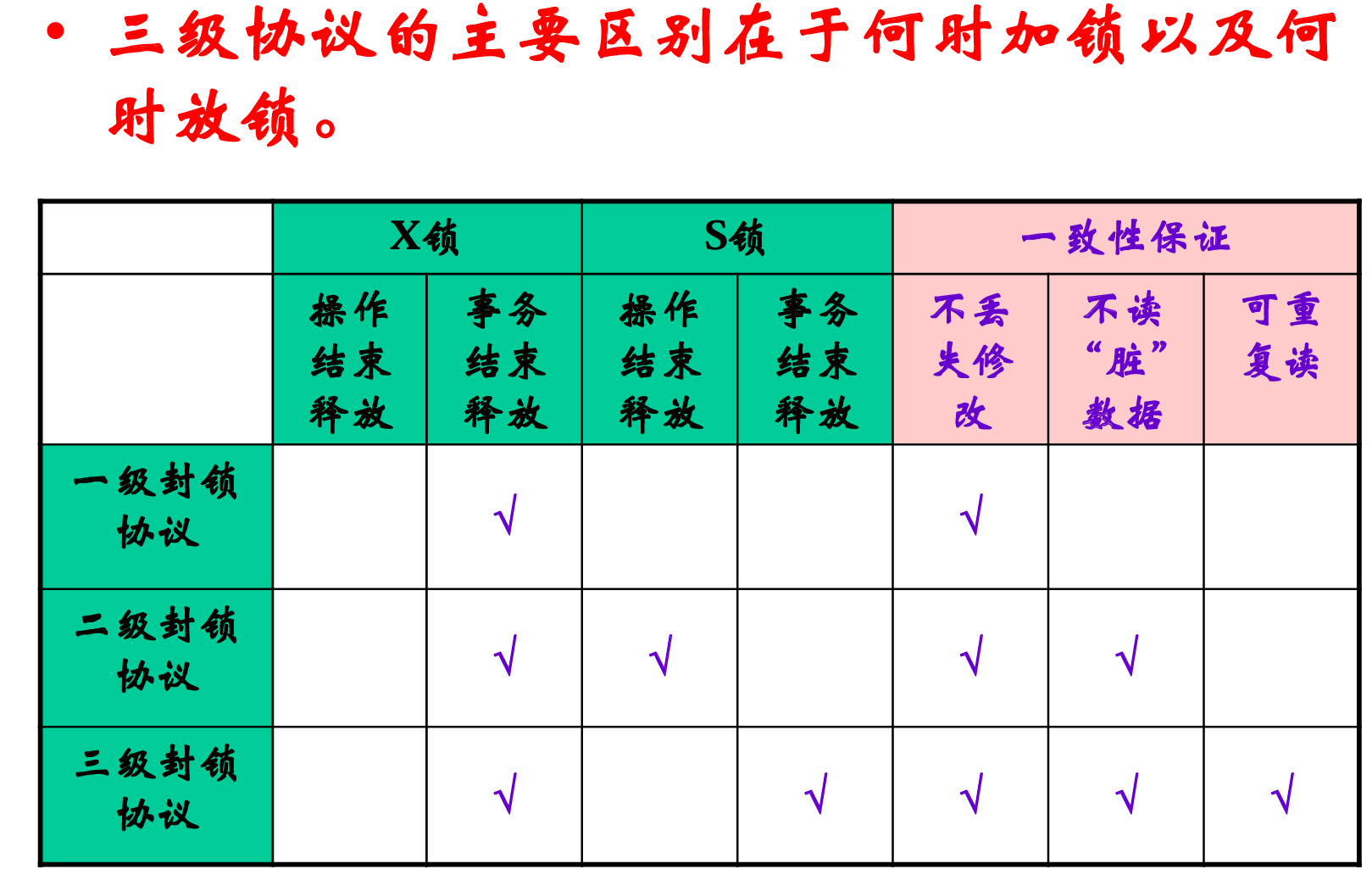
一级:写数据要求X锁
改数据要求加X锁,正常结束事务才释放;
防止丢失修改、可恢复;但是没有保证 可重复读、不读Dirty数据
二级:一 + Read前S锁、读后释放
加上S锁,防止脏数据;但是不保证可重复读
三级:二级S锁到事物结束释放
进一步防止了不可重复读
粒度:封锁对象大小
属性值、属性值集合、元组、关系、某索引项、整个索引、整个 数据库、物理页、块等
大粒度:并发度低,结构简单、开销小
小粒度:并发高,结构复杂开销大
多粒度封锁
同时支持多种封锁粒度 (选择时考虑开销和并发度)
多粒度树:根结点是整个数据库,表示最大的粒度。 叶结点表示最小的粒度。
多粒度封锁协议:每个节点独立加锁,每个点加锁后代也加锁。
因此每个点两个锁:直接被加到身上(显式封锁)、祖先节点被锁(隐式封锁)。效果相同
问题:加锁时进行多项检查——和对象的显式、隐式锁冲突;和后代的显式冲突。
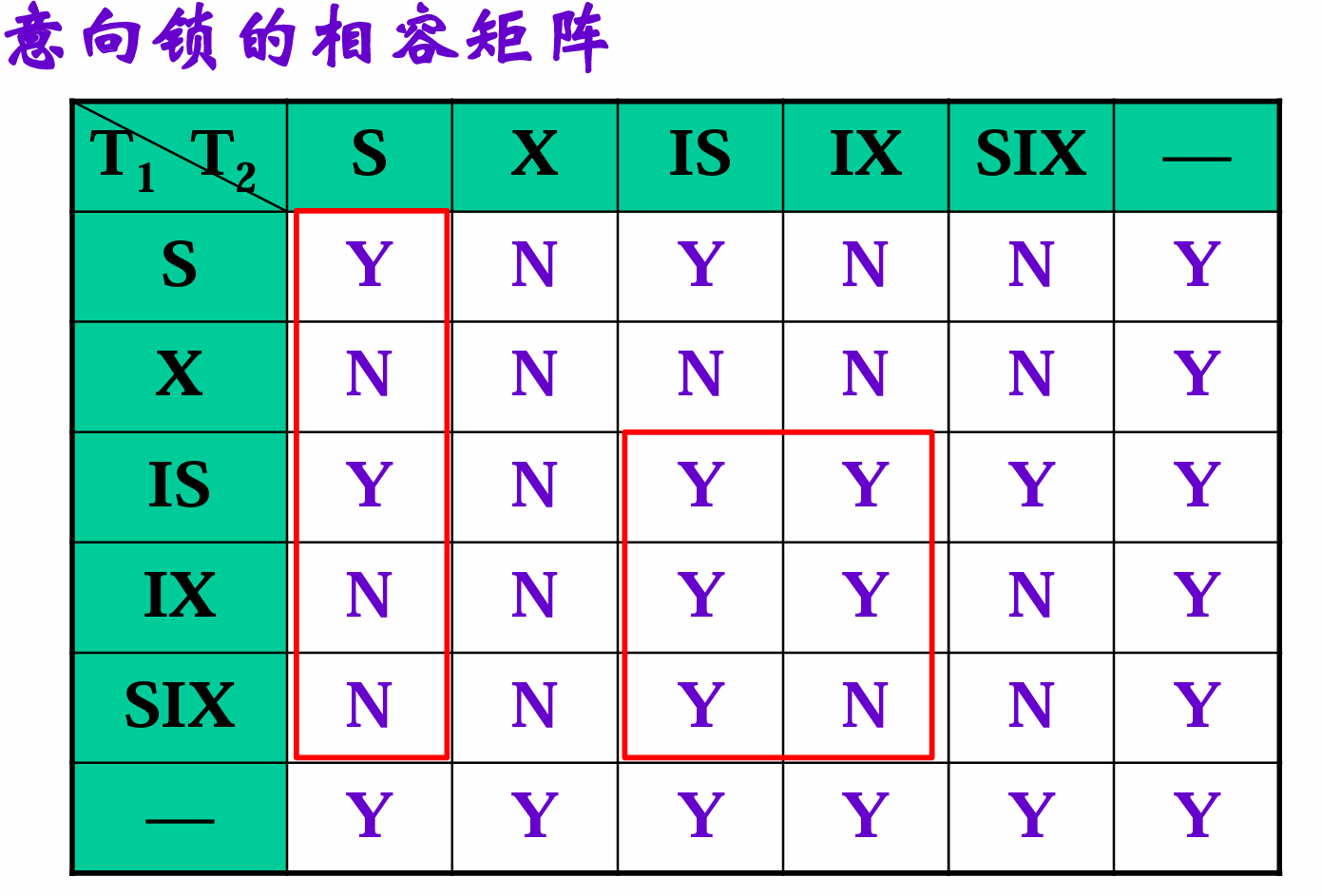
解决:意向锁
意向锁I:该结点的下层结点正在被加锁
IS、IX、SIX(意向共享排他)=S+IX
意向锁加锁可以容忍可能导致冲突的操作,因为如果真正发生冲突,会在子节点发生,届时再取消即可。
活锁
永远等待
解决:先来先服务
死锁
预防死锁: 一次封锁法(一次性把要用数据全加锁,并发性差)、顺序封锁法(规定一个封锁顺序,实习难度大)
死锁检测和破除:超时法、等待图法(看是否有回路)
死锁恢复:撤销一个代价最小的,释放锁,让别的运行。
事务调度
串行调度、并行调度
调度的 事务执行正确性
串行调度一定正确(结果不同,但是保证一致性)。
可串行化调度
如果并行调度和某种串行执行顺序得到的结果相同,则为 可串行化调度 意味着 是 正确调度。
冲突可串行化调度(可串行化的充分条件)
冲突操作:读-写和写-写操作
冲突可串行化:冲突操作顺序不变、可以交换两个不同事物不冲突操作次序,得到另一个串行调度。
两段锁协议:先一起获取(扩展阶段)、再一起释放(收缩阶段)
- 读写之前要获得数据的封锁
- 释放一个锁以后就不会再获取锁
但仍然可能导致死锁
并发调度的可串行性
定理:若所有事务均遵从两段锁协议,则这些事务的所有并发调度都是可串行化的。(充分条件)
其他并发控制方法
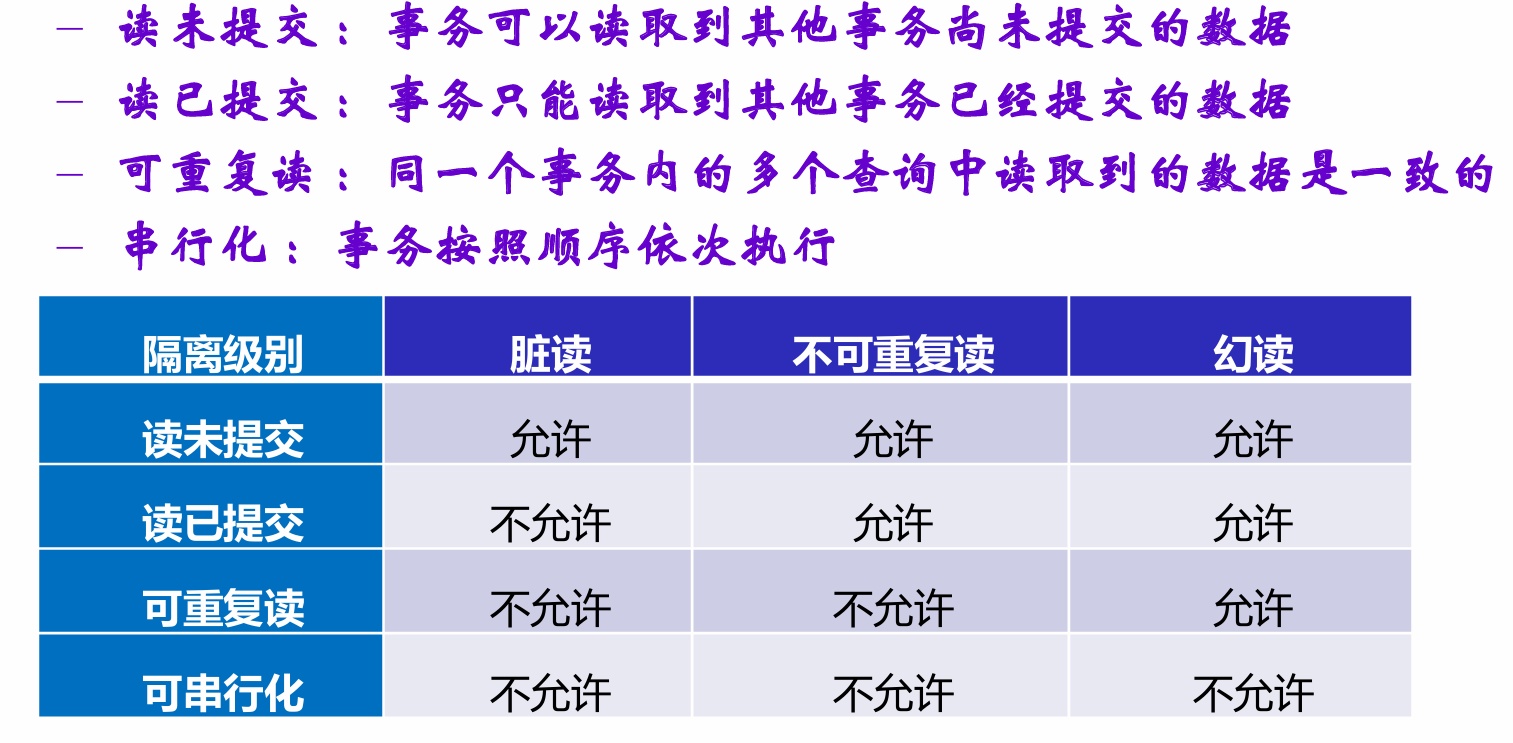
事务隔离级别
四种隔离级别
悲观并发控制 与 乐观并发控制
悲观:事前预防,避免冲突,包含两段锁协议、三级封锁协议
乐观:事后解决,提交时才检查、处理冲突,包含 时间戳排序协议、乐观并发控制协议
时间戳排序协议
给每个事务分配一个全局唯一的时间戳,使得 所有事务有单调顺序。事务只能访问前面的数据,可以产生冲突可串行化调度
冲突时停止一个、回滚,重新调度,新时间戳。
乐观并发控制协议
when 事务冲突较少、执行时间较短
三阶段:读、验证、写

多版本机制 MVCC
维持一个数据多个不同物理版本
写操作:create 新版本
读操作:读取事务开始时最新版本
解决 读写冲突无锁并发,实现 读已提交、可重复读;无法解决:丢失更新
特点:读无需等待、一定成功;写创建新版本不会阻塞其他事务对老版本的读,并发度up
多版本机制+悲观/乐观:前者处理读写、后者处理写写
并发控制协议总结
1.悲观锁
适合事务冲突多,用锁等待方式。
2. 乐观锁
适合事务冲突少,重启事务解决。
3. 时间戳
回滚
4. MVCC多版本
空间复用,结合上面三种提升并发
第十章 新技术
概述
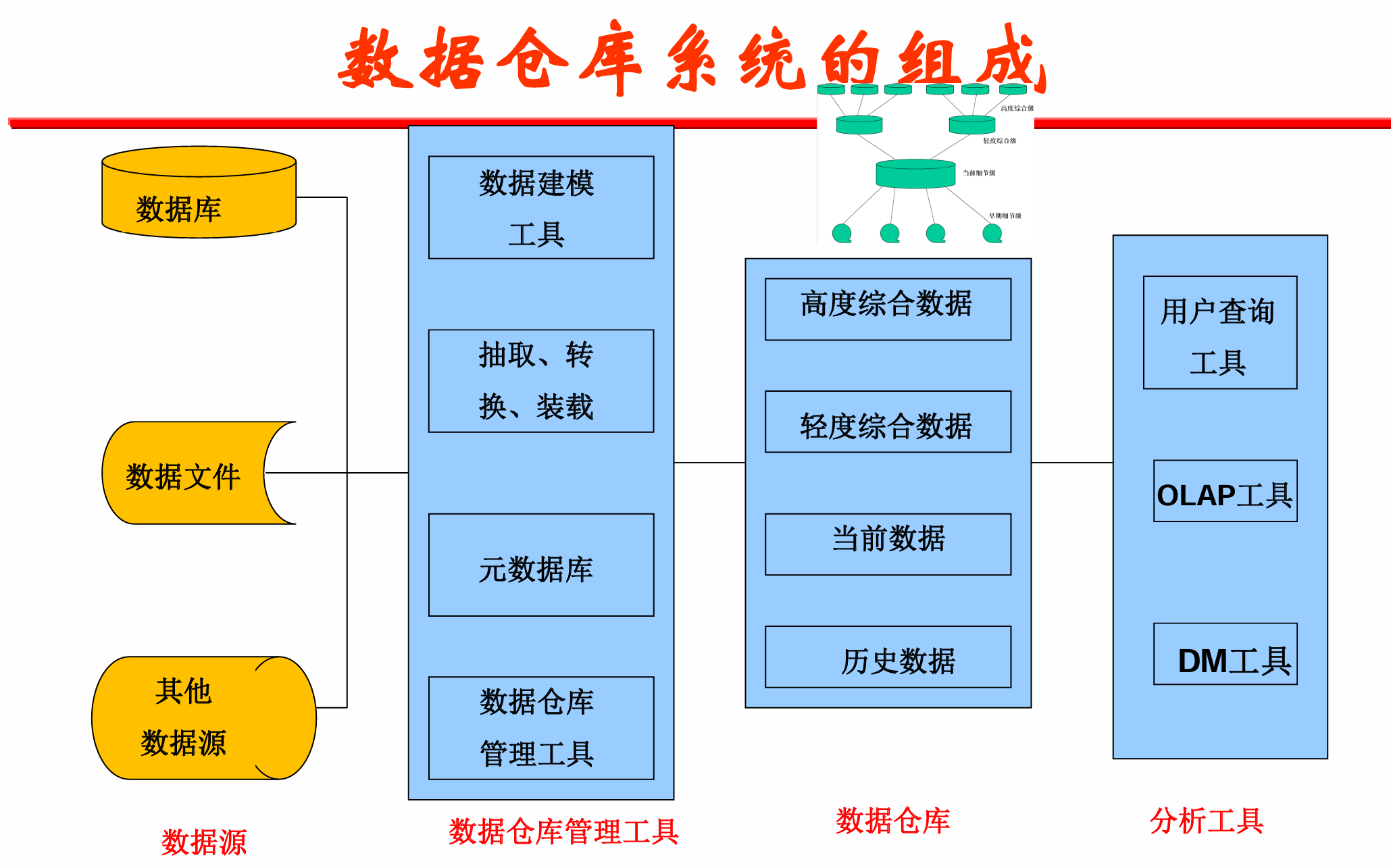
数据仓库
支持管理决策过程的、面向主题的、集成的、随时间而增长的持久数据集合。
仓库上处理:OLAP,联机分析处理;
数据库处理:OLTP,联机事物处理。
非结构化数据管理系统 AUDR
什么乱七八糟的,服了
多种SQL
SQL:传统
NoSQL
Not Only SQL,非关系型数据库,不用SQL
NewSQL
新的可扩展/高性能数据库
传统SQL的ACID特性 + NoSQL海量数据存管能力
分布式数据库
分布性+逻辑整体性
定义
分布在计算机网络不同节点数据组成,每个节点能独立处理(场地自治),可以执行局部应用,同时每个结点也能通过网络通信支持全局应用。
局部应用:只操作一个结点上数据库的应用
全局应用:操作两个或两个以上节点上数据库的应用
要满足同时支持局部应用和全局应用
以 数据分布 为前提,强调 场地自治 和 自治场地之间的协作性。
**场地自治:**每个场地有自己的数据库、一组终端、运行局 部DBMS,是独立的DBS,具有高度自治性。
自治场地之间的协作性:各结点组成整体。整体性的含义是, 从用户角度看,分布式数据库系统逻辑上如同一个集中式数据库一样,用户可以在任何场地执行全局应用。
特点
1. 数据独立性
数据的逻辑独立性和物理独立性
数据的分布独立性(分布透明性):这些分布和安排与用户无关,对用户透明。
2.集中与自治相结合的控制结构
两层次共享
局部共享:局部数据库中多用户共享数据
全局共享:各个节点都存储其他节点的用户共享数据
集中和自治相结合
局部DBMS可独立管理,有自治功能
系统有集中检测结构
3. 适当增加冗余
在不同的结点存储同一数据的多个副本
Pros
- 提高系统的可靠性、可用性
- 提高系统性能:选择最近副本,减少通信代价
Cons
维护代价高
4. 全局一致性、可串行性和可恢复性
体系结构
模式结构
多级模式:
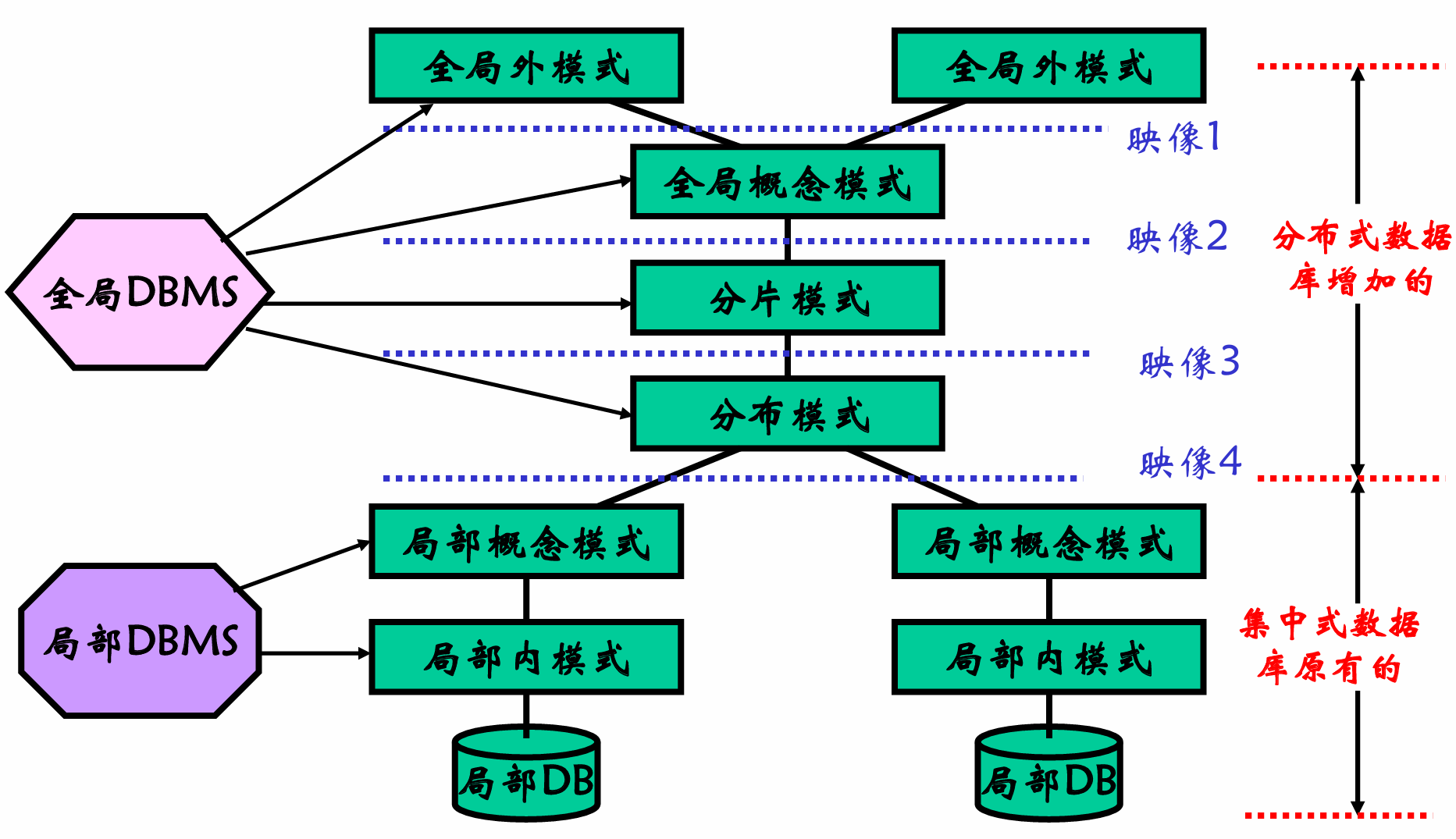
-
全局外模式、 全局外模式 to 全局概念模式 映像(1)
-
全局概念模式
-
分片模式、 全局概念模式 to 分片模式 映像(2)(一对多)
- 分片:每一个全局关系可以分为若干互不相交的部分,每一部分称 为一个片段。
-
分布模式、 分片模式 to 分布模式 映像(3)
- 片段存放节点,以及是否冗余
-
分布模式 to 局部数据库概念模式 映像(4)
- 全局关系片段 to 局部概念模式
数据分片
分片方式
水平、垂直;导出、混合
**水平:**一定条件下,按行分
垂直:按属性集分
导出:水平分,但是条件不在该关系本身属性上,而是参考其他关系的属性条件
混合:上面三者都有
三个约束
完全性、不相交性、可重构性
完全:不能漏
不相交:数据不能重(垂直分时,码除外)
可重构性:可用片段重构全局——垂直join,水平并
分布透明性
透明等级从高到低:分片透明性,位置透明性,局部数据模型透明性
对于用户:不必考虑关系分片、不必考虑存储场地、不必考虑局部数据模型
DDBMS:分布的DBMS
组成
LDBMS:local DBMS,局部DBMS,自治能力
GDBMS:global DBMS,提供分布透明性、全局一致性…
GDD:全局数据字典
CM:通信管理
分类
按全局控制方式:
全局控制集中
- GDBMS只在一个节点,GDD也只有一个、在此节点
- 控制简单,容易实现
- 该节点出问题,就完了;容易形成瓶颈
全局控制分散(完全分布的GDBMS)
- 每个节点都有GDBMS和GDD
- 优点:结点独立,自治性强,单个结点出现问题不会使系统瘫痪;
- 缺点:全局控制的协调机制和一致性维护都比较复杂。
全局控制部分分散的DDBMS
- 上面二者之间,部分节点有
按局部DBMS类型
同构型DDBMS:每个节点有相同DBMS
异构型DDBMS:可能有不同DBMS
主要技术
分布查询处理、优化;分布事务管理
分布查询处理和优化
查询类型
局部、远程:只涉及单个节点数据,直接用LDBMS
全局:多个节点数据
过程
- 查询分解:分解成子查询,每个子查询只涉及一个节点的数据(选择开销最省的片段),由LDBMS处理
- 选择执行次序:连接、并 的 顺序
- 选择执行方法:存取路径、算法和执行方法
优化目标
I/O代价+CPU代价+通信代价
分布优化+局部优化
更具体:连接查询优化
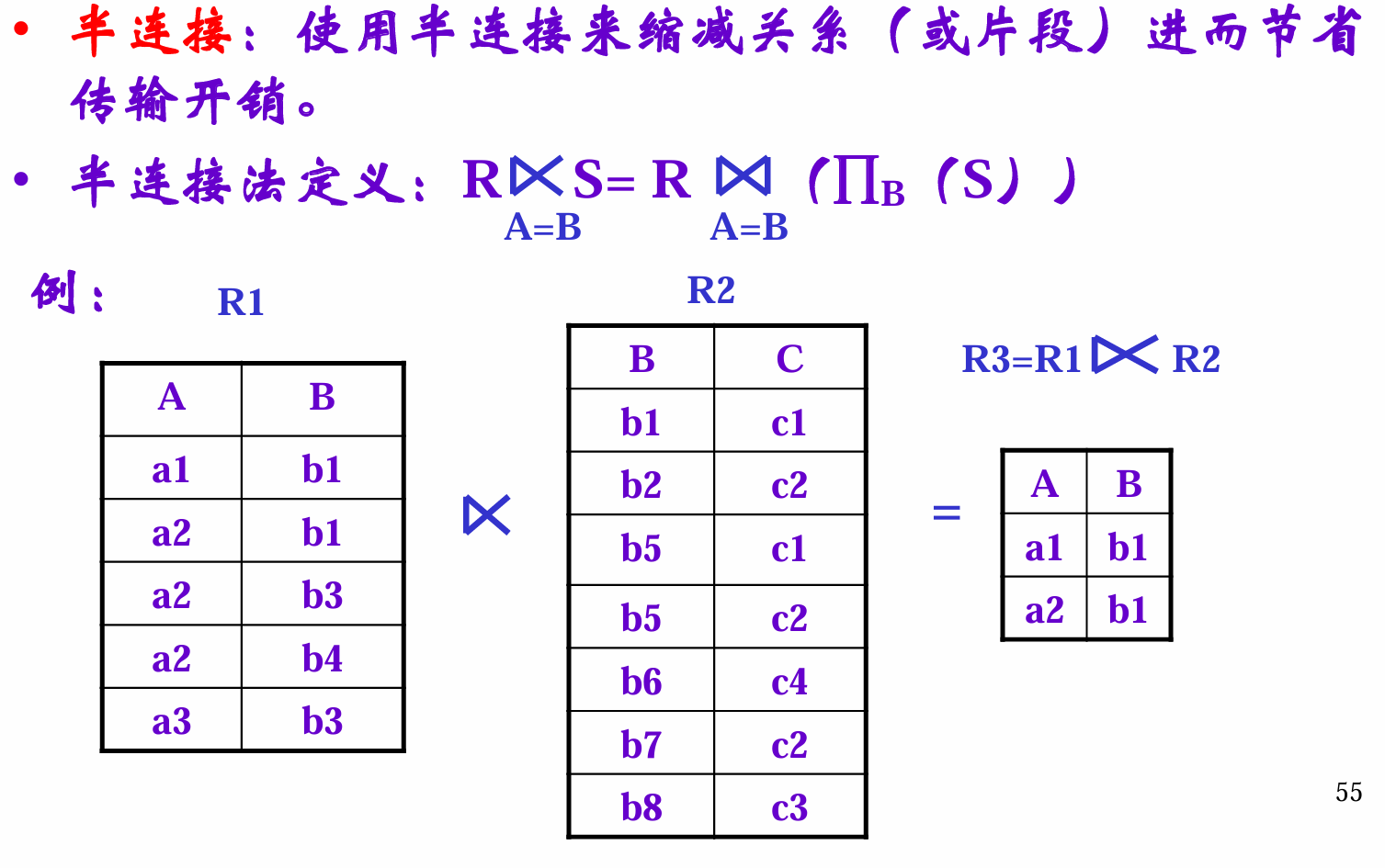
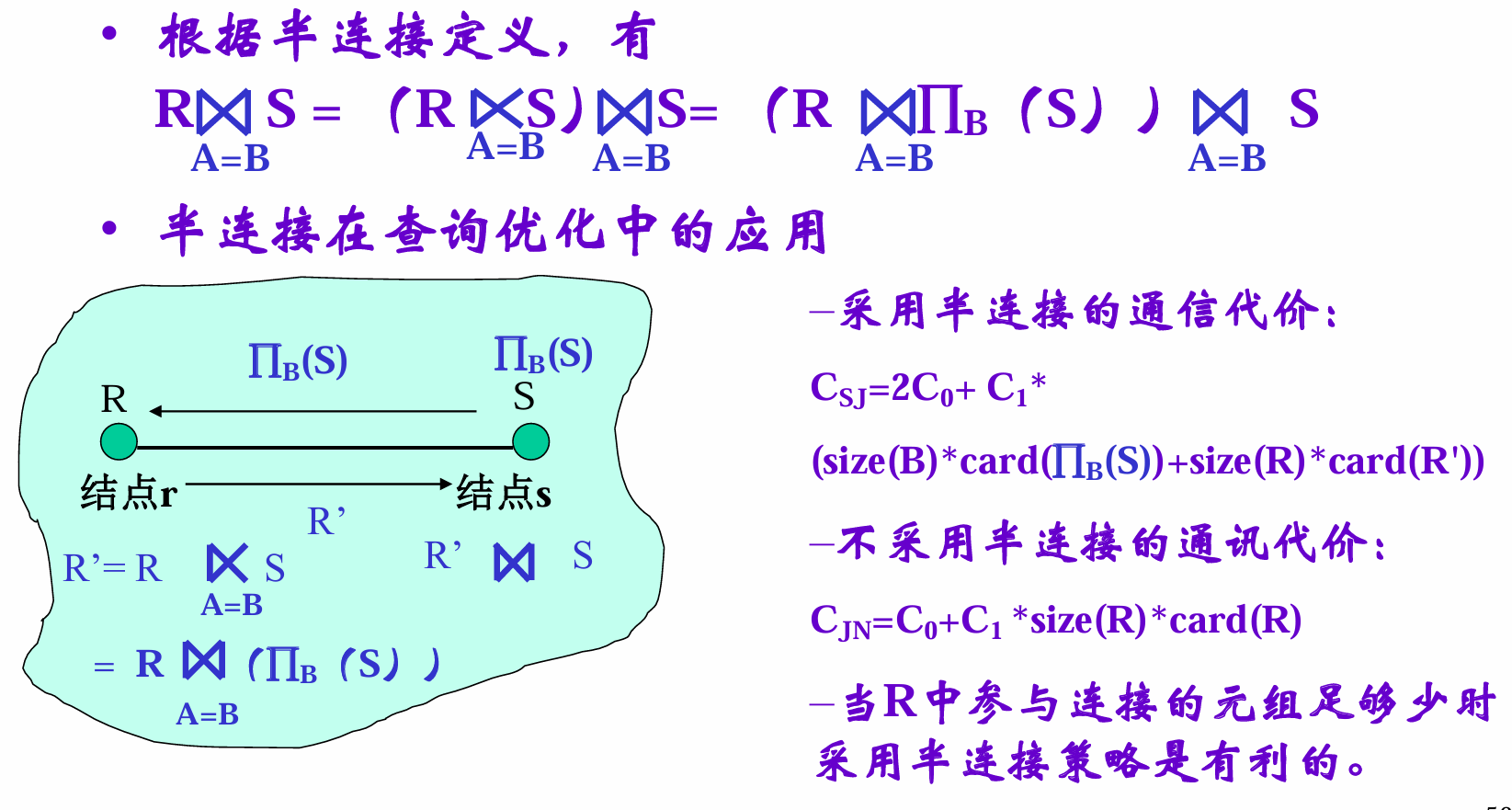
半连接
就是对于一半的部分,projection一下然后连接
分布事务处理
一个全局事务被划分为在许多结点上的子事务。
分布事务的原子性是:组成该事务的所有子事务要么一致地全部提交,要么一致地全部回滚。
事务的恢复和并发控制
分布事务恢复
每个场地:局部事务管理器,管理局部子事务、相互协调以保证分布事务原子性
两段提交协议
局部参与者分为:1个协调者,n个参与者
协调者:最后决定事务提交 or 撤销
参与者:子事务的执行、各自局部数据库的写操作
两阶段:
- 协调者征求参与者意见:规定时间内一致通过,ok提交;否则撤销
- 协调者决定、写log,发给参与者;参与者log、应答、执行;收到所有参与者应答->结束
并发控制
封锁——引起全局死锁
多副本封锁的可能方法
- 写:申请所有副本的X;读:申请某副本S;
- 读写对大多数副本申请锁
- 规定主副本(某个场地),读写都要对主副本封锁
全局死锁
死锁检测和解除
死锁预防:排序事务、单向等待。
云数据库
云数据库服务 RDS
云服务提供商基于虚拟化技术,提供了数据库服务DataBase-as-a-Service,DBaaS
云数据库服务 和 云原生数据库技术
一主多从的结构
问题:
资源利用率、扩展性、可用性
云原生数据库
数据库从设计之初即考虑到云的环境,为云而设计,架构为云设计
数据库内部计算与存储分离

如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !